![]() В одной далёкой-далёкой галактике появился один очень-очень странный проект, под который было приобретено не менее странное оборудование, которое разные странные люди почему-то называли сервером. И вот, в один из заснеженных августовских дней, попал этот сервер модели HP/HPE ProLiant DL20 Gen10 ко мне с постановкой задачи, согласно которой на сервер нужно установить ОС Debian Linux и некоторое прикладное ПО.
В одной далёкой-далёкой галактике появился один очень-очень странный проект, под который было приобретено не менее странное оборудование, которое разные странные люди почему-то называли сервером. И вот, в один из заснеженных августовских дней, попал этот сервер модели HP/HPE ProLiant DL20 Gen10 ко мне с постановкой задачи, согласно которой на сервер нужно установить ОС Debian Linux и некоторое прикладное ПО.
Имея некоторый опыт работы с RAID-контроллерами HPE Smart Array, я предположил, что задача будет решена без каких-либо затруднений. Однако, когда я добрался до инвентаризации комплектации полученной "железяки", меня ждал сюрприз. Оказалась, что сервер в своей поставке имеет два дисковых накопителя SATA HDD и, вместо аппаратного RAID-контроллера, оснащён базовой опцией программного RAID - HPE Smart Array S100i SR Gen10 SW RAID.
Если заглянем в спецификацию QuickSpecs по данной модели сервера, то увидим некоторые замечания относительно опции программного RAID:
- The S100i supports windows only.
- For Linux users, HPE offers a solution that uses in-distro open-source software to create a two-disk RAID 1 boot volume. For more information visit: https://downloads.linux.hpe.com/SDR/project/lsrrb/
Пройдя по последней ссылке, мы можем найти документ, описывающий набор костылей от HPE под названием LSRRB (Linux Software RAID - Redundant Boot), адаптированный под системы Red Hat Enterprise Linux 7.3 и SuSE Linux Enterprise Server 12.2. В нашем же случае на сервер необходимо установить ОС Debian 10 (Buster) GNU/Linux и это несколько меняет набор необходимых действий.
В качестве решения по защите данных на сервере в случае отказа одного из дисков мы воспользуемся возможностями программной реализации RAID в Linux - mdraid. При этом программные RAID-массивы RAID-1 мы будем делать не из дисков в целом, а из отдельных, заранее созданных, дисковых разделов, а загрузочные разделы EFI System Partition (ESP) будут незеркалируемыми.
Раздел ESP в нашем случае незеркалируемый, так как загрузка EFI работает только с физическими устройствами на начальном этапе включения сервера, когда управляющий код Linux ещё не загружен и не инициализированы программные RAID-массивы. Хотя следует признать, что способы размещения раздела ESP на зеркалируемом разделе существуют, однако выглядят они больше, как экстремальное развлечение с учётом костылей, которыми всё это обставляется, а также с учётом разных страшных историй про потерянные супеблоки.
По условиям нашей задачи, сервер с установленной Debian Linux должен содержать 3 раздела:
- Загрузочный раздел EFI (ESP) размером в 250MB
- Раздел подкачки (Swap) размером в 4GB
- Корневой раздел с Linux и ПО, под который отдаётся всё оставшееся пространство диска
Если с необходимостью зеркалирования корневого раздела с ОС Linux и рабочим ПО всё понятно, то относительно раздела подкачки Swap есть мнения, что включение в RAID этого раздела лишено смысла. Однако, если не зеркалировать этот раздел, то может получиться так, что процессы, использующие swap на диске, который внезапно выйдет из строя, могут упасть, что, само по себе, при неудачном стечении обстоятельств может привести к порче каких-либо данных. Чтобы этого не допускать, мы настроим отдельный RAID-1 для раздела подкачки.
Далее, в рамках нашей задачи, мы по порядку рассмотрим следующие процедуры:
- Подготовка аппаратной платформы сервера
- Подготовка дисков сервера к установке Debian Linux на программный RAID
- Установка Debian 10 (Buster) GNU/Linux
- Послеустановочная настройка загрузчика UEFI
- Проверка обработки отказа дисков в RAID
- Замена неисправного диска в RAID
Подготовка аппаратной платформы сервера
Работу с любым сервером начинаем с доведения микрокода аппаратных компонент сервера до актуальных версий.
Для серверов на базе платформы HPE ProLiant G10 имеется загружаемый ISO-образ с комплектом обновлений микрокода и драйверов - Service Pack for ProLiant (SPP). Актуальную версию пакета можно найти по ссылке: Gen10 Service Pack for ProLiant (SPP) Version 2020.03.0.
С помощью утилиты HPE USB Key Utility for Windows 3.0.0.0 (12 Jul 2017) мы можем подготовить загрузочный USB-накопитель, на который будет записано содержимое пакета SPP.
Загружаем сервер с подготовленного USB-накопителя и запускаем сессию обновления микрокода для всех поддерживаемых устройств сервера.
Утилита Smart Update Manager проведёт загрузку метаданных о всех доступных обновлениях микрокода, входящих в текущую версию пакета SPP, сопоставит их с аппаратной частью сервера и проведёт обновление.
В случае выбора варианта с автоматическим обновлением, по окончании процесса обновления микрокода сервер перезапустится.
После перезапуска сервера извлекаем загрузочный USB-накопитель с SPP и, на этапе инициализации аппаратной платформы, нажимаем F9, чтобы попасть в главное меню "System Utilities".

В меню переходим последовательно в "System Configuration" > "BIOS/Platform Configuration (RBSU)" > "Storage Options" и выбираем опцию "SATA Controller Options".
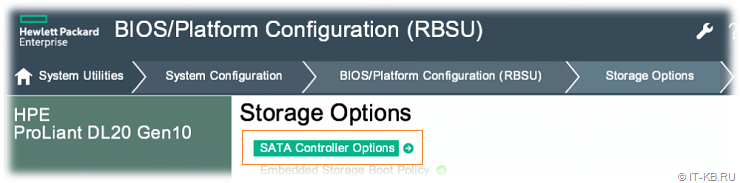
Меняем в опции "Embedded SATA Configuration" режим "Smart Array SW RAID Support" на режим "SATA AHCI Support".
Клавишей F10 сохраняем сделанные изменения и выходим из RBSU.
Обратите внимание на то, что сделать данное переключение режима работы SATА контроллера обязательно до того, как начинать какие-либо дальнейшие действия с дисками и установкой Linux. А после того, как ОС будет установлена и в Linux будет собран программный RAID, изменять настройки режима SATA крайне не рекомендуется, поэтому лучше сразу ограничить доступ к настройкам RBSU от любителей "крутить всякие крутилки".
Подготовка дисков сервера к установке Debian Linux на программный RAID
Нужную нам разметку диска с созданием всех необходимых разделов можно выполнить непосредственно в процессе установки ОС даже в графическом инсталляторе Debian Buster. Однако мои практические эксперименты с использованием такого варианта разметки показали то, что он не лишён своих недостатков и не даёт нужной гибкости, которую мы имеем в случае предварительной разметки диска в режиме загрузки с Debian Live CD.
При выборе дистрибутива Debian Linux следует помнить, что в стандартный дистрибутив этой ОС не включены никакие проприетарные драйверы и файлы поддержки микрокода. А учитывая то, что в нашем случае используется сервер HPE, где могут быть устройства, требующие проприетарного кода, нам лучше сразу скачивать загрузочный образ дистрибутива Debian, укомплектованный "non free" драйверами, а также имеющий режим загрузки Debian Live. Текущая версия такого образа для 64-разрядных систем доступна по ссылке: Debian Live (amd64, non-free)
Здесь мы можем увидеть множество Live-дистрибутивов, собранных с поддержкой разных графических сред исполнения, таких как Gnome, KDE и т.п. Так как в рамках нашей задачи графическая среда не требуется, а все операции по управлению разделами будут проводится утилитами командной строки, то и загружать можно самый простой стандартный дистрибутив вида debian-live-10..-amd64-standard+nonfree.iso.
Полученный загрузочный образ Debian Live записываем на USB-накопитель, например, с помощью утилиты Rufus , загружаем сервер с USB-накопителя и в главном меню загрузки Grub выбираем вариант "Debian GNU/Linux Live"…
В ходе загрузки Live-система автоматически получит адрес с DHCP и сконфигурирует сетевой адаптер для работы с локальной сетью.
В дальнейшем нам потребуется до-установить в Live-систему некоторые пакеты из online-репозиториев Debian. Эти дополнительные пакеты пригодятся нам для работы с разделами дисков. Поэтому на время у сервера должен быть прямой доступ в Интернет.
Дождёмся окончания загрузки Debian Live и появления приглашения командной строки. Первой командой повысим себе привилегии до уровня супер-пользователя (root):
$ sudo su -
Теперь с помощью пакетного менеджера apt обновляем информацию о пакетной базе и до-устанавливаем утилиты, которые нам потребуются для работы
# apt-get update
# apt-get install mdadm gdisk dosfstools -y
После установки пакетов можно отключить на шлюзе для данного сервера прямой доступ в Интернет.
Получим информацию о блочных устройствах, доступных нашей Linux системе:
# lsblk

Как видим, система обнаружила и обозначила два наших физических SATA диска, как sda и sdb.
В нашем случае оба диска являются пустыми неразмеченными дисками. В случае же, если диски ранее где-то использовались и на них были созданы какие-то разделы, то нам потребуется очистить старую информацию о разделах с обоих дисков. Сделать это можно, например, так:
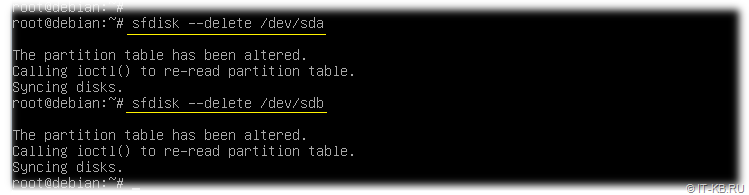
# sfdisk --delete /dev/sda
# sfdisk --delete /dev/sdb
Выполним создание нужных нам разделов на первом физическом диске командой вида:
sgdisk -n {номер раздела}:{начальный сектор}:{конечный сектор} -t {номер раздела}:{hex-код типа раздела} -c {номер раздела}:{имя раздела в GPT} /dev/{размечаемый диск}
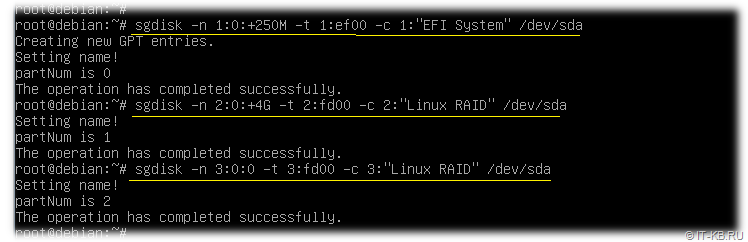
В нашем случае, для трёх нужных нам разделов (250MB под ESP, 4GB по Swap, остальное пространство под корневую ФС Linux) на первом диске (/dev/sda), выполняются команды:
# sgdisk -n 1:0:+250M -t 1:ef00 -c 1:"EFI System" /dev/sda
# sgdisk -n 2:0:+4G -t 2:fd00 -c 2:"Linux RAID" /dev/sda
# sgdisk -n 3:0:0 -t 3:fd00 -c 3:"Linux RAID" /dev/sda
Здесь в ключе -t указывается тип раздела, который в общем случае "ef00" для EFI и "fd00" для разделов, которые будут являться участниками Linux RAID.
В рассматриваемом примере для дальнейшего создания RAID разделов будет использоваться два физических диска идентичного размера. Однако Linux RAID можно собирать и из физических дисков разного объёма, при условии, что раздел RAID не будет превышать ёмкости наименьшего физического диска. И если изначально диски, которые мы собираемся использовать, имеют разный объём, то в качестве первого диска при создании разделов, нужно использовать диск меньшего объёма. Это важно по той простой причине, что конфигурацию созданных разделов первого физического диска на следующем шаге мы будем копировать на второй диск.
Клонируем таблицу разделов (ключ -R) с первого диска (/dev/sda) на второй диск (/dev/sdb) с регенерацией идентификаторов разделов (в контексте GPT) на втором диске (ключ -G):
# sgdisk /dev/sda -R /dev/sdb -G

Давайте посмотрим, что у нас получилось:
# fdisk -l
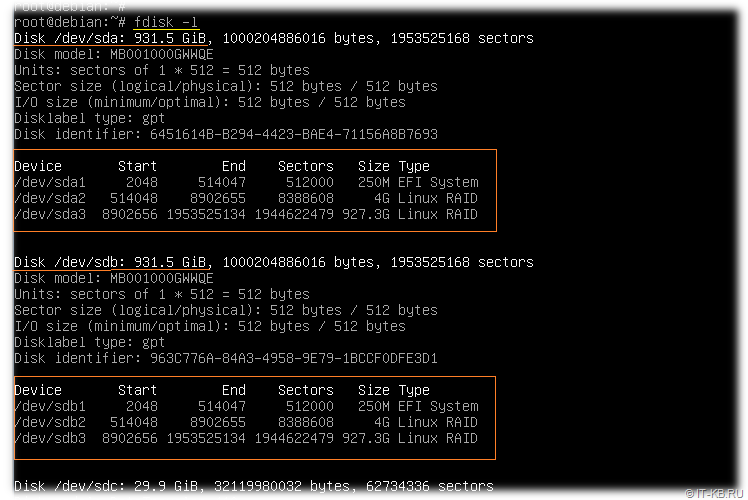
Как видим, теперь у нас на обоих дисках sda и sdb имеются идентичные по размеру и типу разделы, из которых в дальнейшем мы сделаем 2 программных RAID-диска (зеркальный раздел sda2 <-> sdb2 под Swap, и зеркальный раздел sda3 <-> sdb3 под корневой раздел с Linux и ПО)
Создаём RAID-разделы (устройства md0 и md1) уровня RAID1 из пар идентичных разделов с разных физических дисков:
# mdadm --create /dev/md0 --bitmap=internal --level=1 --raid-disks=2 /dev/sda2 /dev/sdb2
# mdadm --create /dev/md1 --bitmap=internal --level=1 --raid-disks=2 /dev/sda3 /dev/sdb3
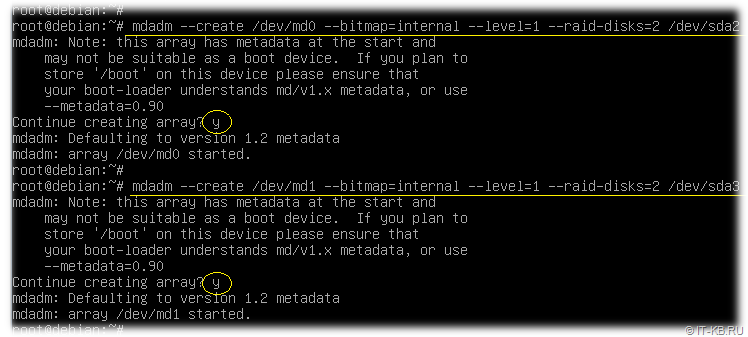
После выполнения команд создания RAID-разделов, автоматически запустится процесс синхронизации. Посмотреть статус этого процесса можно командой:
# cat /proc/mdstat
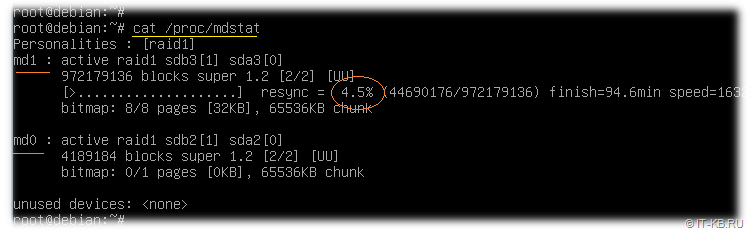
Дожидаемся, когда процесс синхронизации разделов в RAID дойдёт до 100%.
Чтобы в реальном режиме времени наблюдать за процессом, можно выполнить команду вида:
# watch cat /proc/mdstat
После того, как RAID-устройства /dev/md0 и /dev/md1 окончили синхронизацию, проверим их статус:
# mdadm --detail /dev/md0
# mdadm --detail /dev/md1
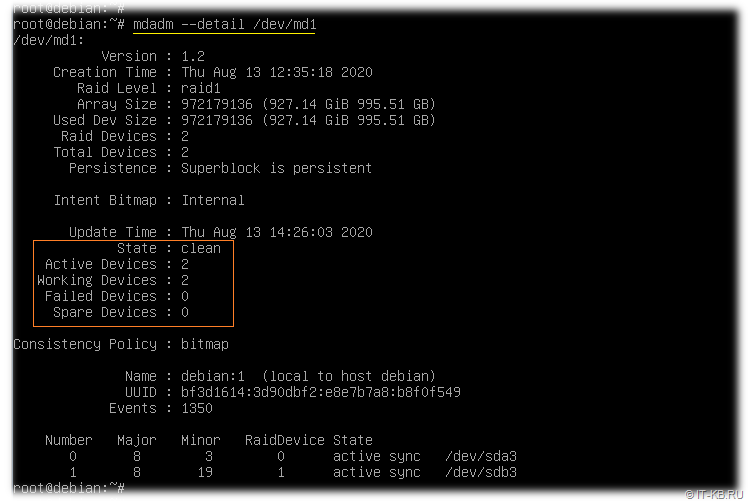
RAID-разделы подготовлены и теперь можно переходить к процессу установки ОС Debian.
В процессе установки загрузчик EFI будет записан на первый раздел (тот, что размером 250MB) на первом диске (/dev/sda1). Раздел подкачки будет создан на первом зеркалируемом разделе (программном RAID-устройстве /dev/md0), а раздел с ОС Linux будет размещён на втором зеркалируемом разделе (/dev/md1)
Отправляем сервер в перезагрузку, чтобы завершить сеанс работы в режиме Debian Live
# reboot
Установка Debian 10 (Buster) GNU/Linux
Загружаем сервер с установочного накопителя Debian Buster. В качестве установщика можем использовать всё тот же USB-накопитель с Debian Live, только при запуске в начальном меню Grub нужно выбрать режим установки ОС, например, "Graphical Debian Installer".
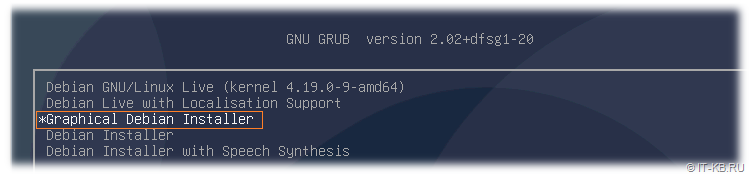
В графическом инсталляторе Debian пройдём несколько стандартных этапов. На этапе "Select a language" выберем в качестве языка, используемого для процесса установки, "English".

На этапе "Select your location" в качестве нашего географического размещения выбираем последовательно из предложенных списков пункты: "other" > "Europe" > "Russian Federation".
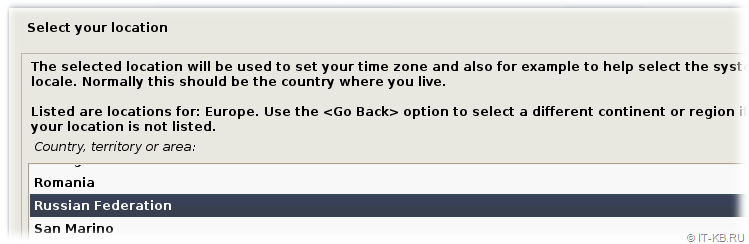
На этапе "Configure locales" в качестве основной локализации системы сервера выбираем "en_US.UTF-8".

На этапе "Configure the keyboard" выбираем текущую раскладку клавиатуры, например, "Russian" и сочетание клавиш для переключения между языками.

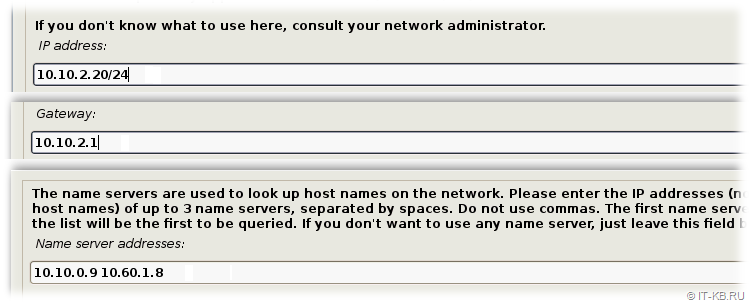
На этапе "Configure the network" инсталлятор проверит все доступные сетевые интерфейсы и попытается выполнить авто-конфигурацию настроек IP, получив данные с DHCP-сервера. В нашем примере, перед установкой ОС сервер уже был переключен в изолированный VLAN, где DHCP не работает и требуется ручная настройка сети. Выберем интерфейс, который будет использоваться в качестве основного интерфейса сервера и перейдём к его ручной настройке "Configure network manually".

Далее последовательно зададим IP-адрес сервера с маской сети, IP-адрес шлюза сети и IP-адресы DNS-серверов, разделённые пробелами.
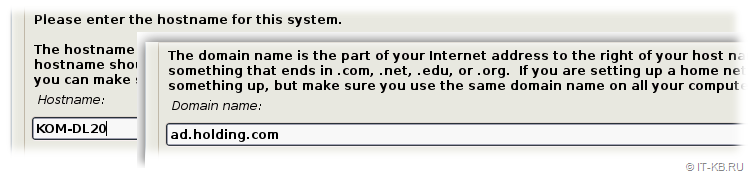
Затем укажем имя сервера, и имя основного доменного суффикса, если требуется.
После окончания установки ОС вместо стандартного механизма разрешения имён рекомендуется настроить службу DNS-клиента systemd-resolved, так как она имеет встроенный механизм кеширования разрешаемых в DNS имён, что само по себе благотворно влияет на DNS-серверы с точки зрения снижения нагрузки.
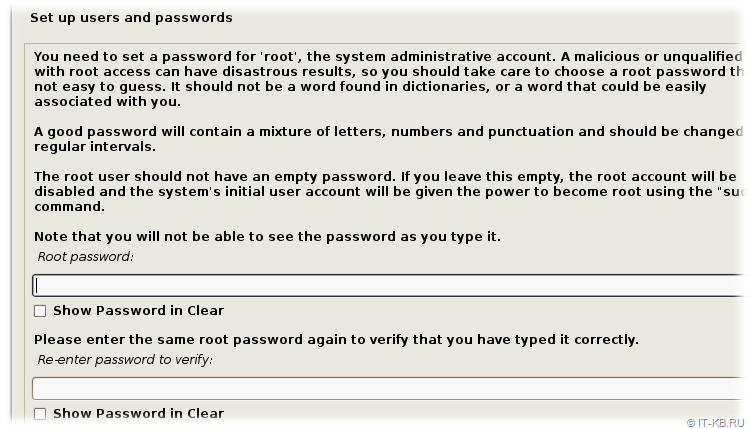
На следующем этапе "Set up users and passwords" мы получим запрос на ввод пароля с правами супер-пользователя c предопределённым именем "root". Учитывая то, что данного пользователя в целях безопасности рекомендуется выключать, а для повышения привилегий использовать механизм "sudo", здесь мы намеренно не укажем никакого пароля. Увидев пустой пароль, инсталлятор Debian переведёт учётную запись "root" в выключенное состояние.
Далее нам будет предложено создать произвольного рядового пользователя для входа в систему. Укажем любое полное имя и соответствующий ему логин для входа (регистро-зависимое значение), а также два раза введём пароль для данного логина.
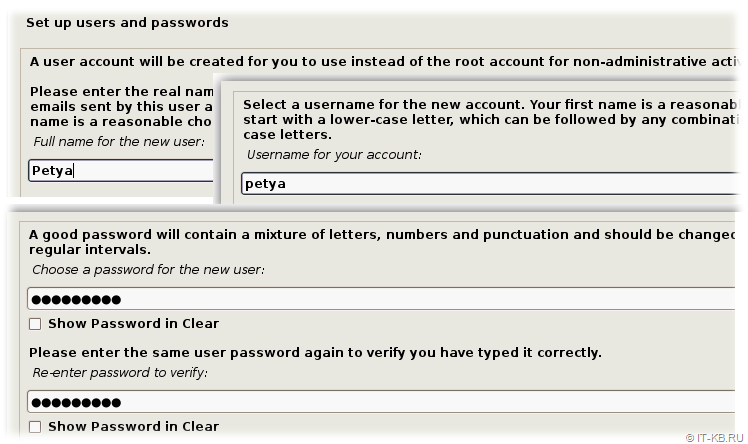
Учитывая то, что для учётной записи пользователя "root" мы не указали пароля и она будет отключена, создаваемый нами рядовой пользователь будет автоматически наделён возможностью повышать свои привилегии в системе до уровня супер-пользователя с использованием команды "sudo" для любых операций.
На этапе "Configure the clock" нам будет предложено выбрать текущий часовой пояс для настройки системы.

В Debian Linux клиент NTP в конфигурации по умолчанию будет пытаться достучаться до NTP-серверов в Интернете. При наличии в сети предприятия локальных NTP-серверов после окончания установки ОС рекомендуется настроить службу синхронизации времени systemd-timesyncd.
Теперь мы подошли к самому интересному этапу разметки дисков "Partition disks". В перечне доступных методов разметки выбираем режим ручной разметки "Manual".
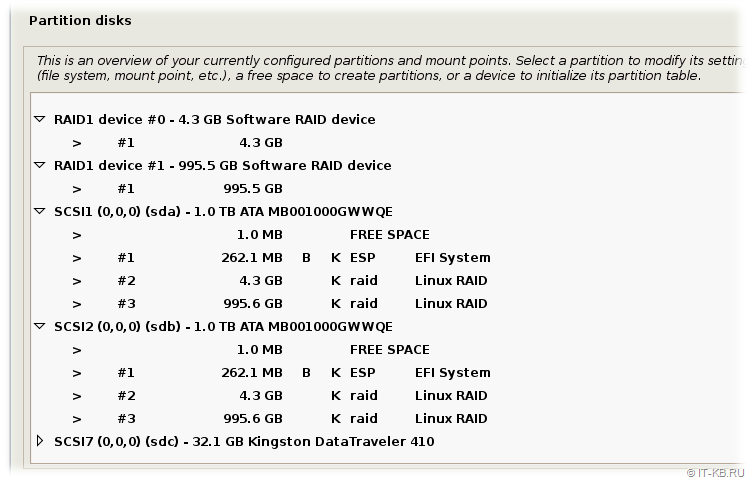
Откроется список обнаруженных дисковых устройств. Здесь мы осмотримся и обнаружим ранее созданные нами разделы на первом диске sda, идентичную разметку диска sdb и два уже готовых к работе RAID-устройства.
Выбираем раздел, который должен использоваться под загрузчик EFI (раздел ESP) на первом диске (sda) и нажимаем кнопку "Continue", чтобы перейти к настройке этого раздела.
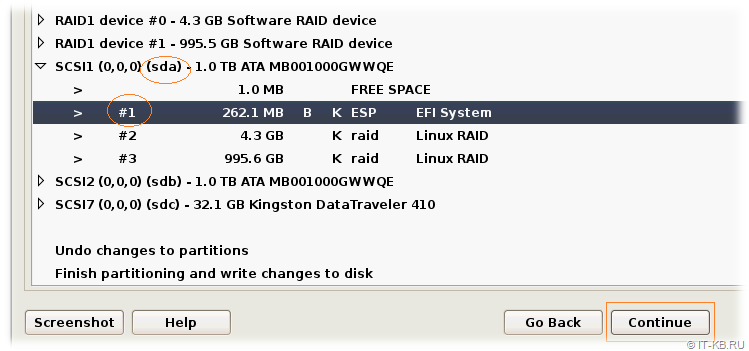
Убедимся в том, что инсталлятор пометил этот раздел как наиболее подходящий под "EFI System Partition" с включенным флагом загрузки "Bootable flag" в "on". То есть, фактически, в нашем случае можно здесь ничего не менять. Завершаем работу с разделом, выбрав внизу экрана пункт "Done settings up the partition".
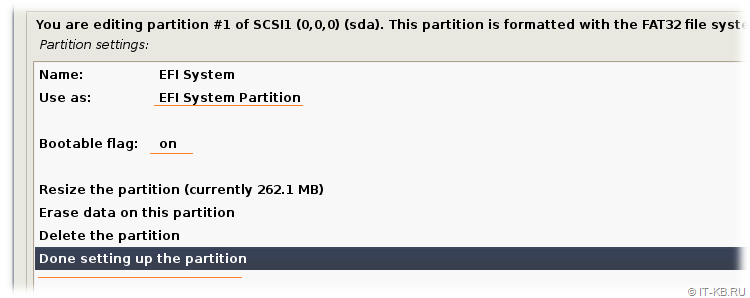
Вернувшись обратно в область разметки дисков, выберем первый и единственный 4GB раздел на RAID-устройстве #0 и перейдём к его настройке.
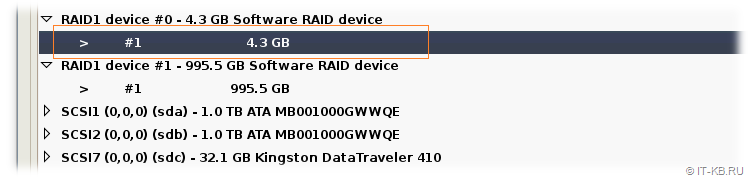
В окне настроек раздела в поле "Use as" будет определено значение "do not use". С помощью клавиши "Enter" или "Space" щелкнем по этому значению и из предопределённого списка выберем тип раздела "swap area", то есть определим данный зеркалируемый раздел под раздел подкачки Linux.
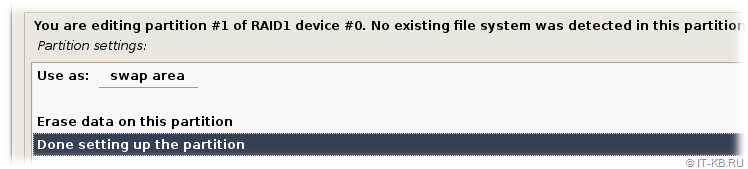
Завершим настройку раздела и вернёмся в область разметки дисков, где следующим шагом выберем первый и единственный раздел на RAID-устройстве #1.
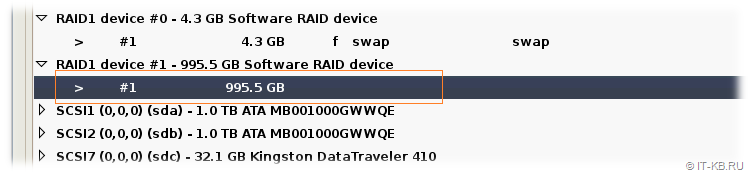
Откроется окно настроек раздела, в котором в поле "Use as" изменим назначение раздела под журналируемую файловую систему Ext4 – "Ext4 journaling file system". В качестве точки монтирования в файловой системе Linux, связанной с этим разделом ("Mount point"), выберем "/ - the root file system" и сохраним настройки через "Done settings up the partition".
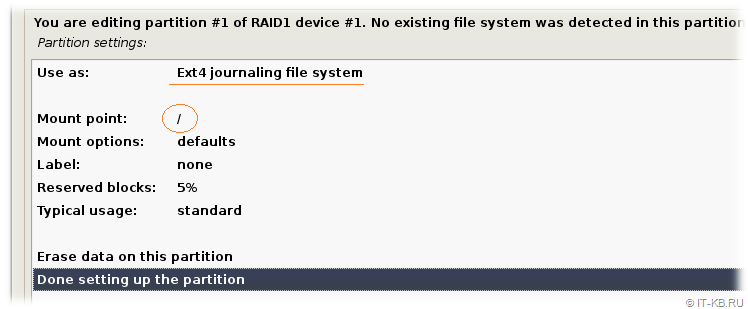
На этом изменение параметров разметки дисков в рамках задачи установки ОС закончены. Обратите внимание на то, что на данном этапе со вторым физическим диском sdb и его разделами мы не выполняем вообще никаких манипуляций.
Выбираем пункт записи настроек на диски "Finish partitioning and write changes to disk".
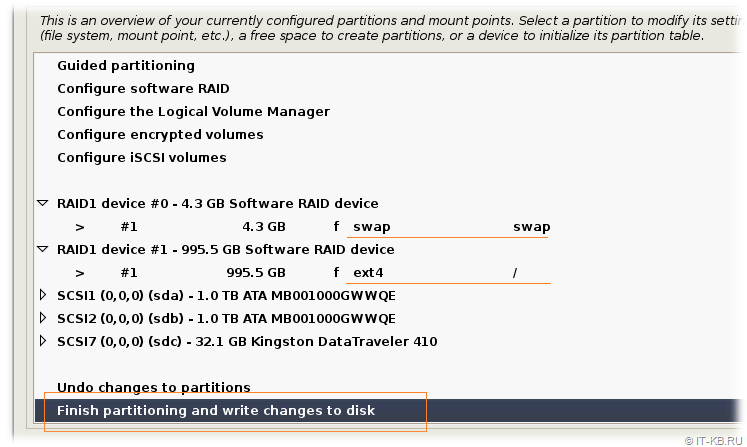
Инсталлятор покажет нам статусное окно об изменениях разметки дисков и задаст вопрос о сохранении, на который отвечаем утвердительно.
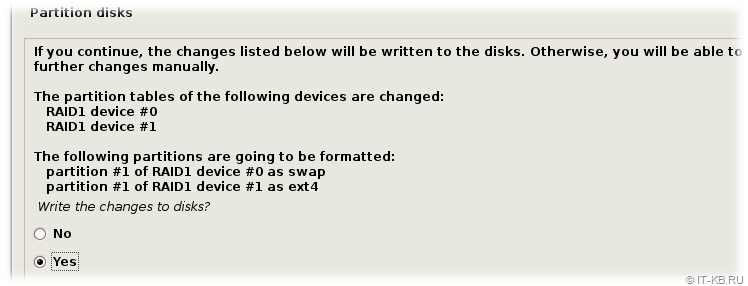
Сразу после этого начнётся процесс установки ОС на RAID-раздел, выбранный нами в качестве точки монтирования корневой ФС ("/").
Далее инсталлятор задаст вопрос о необходимости подключения сетевых зеркал с пакетной базой Debian. На данном этапе можем отказаться от этого, так как подключение репозиториев Debian и обновление пакетной базы можно будет выполнить после окончания процесса установки.

Дожидаемся завершения процесса установки ОС и сообщения о том, что теперь можно извлечь установочный носитель и перезагрузить сервер, после чего жмём кнопку "Continue" и ждём, когда сервер автоматически перезагрузится.

После перезагрузки сервера система должна успешно загрузиться с помощью ESP раздела, который был создан на первом диске. EFI-загрузчик в ESP, в свою очередь, должен успешно запустить ОС Linux c программного RAID-раздела.
Войдём в систему с именем пользователя и паролем, которые были нами указаны в процессе установки ОС. Для проверки наличия прав администратора у нашего пользователя, выполним команду повышения привилегий до уровня root-пользователя с помощью "sudo":
$ sudo su -
Подключим стандартные репозитории Debian Buster, как это описано в заметке "Как подключить стандартные репозитории Debian 10 Buster" и произведём обновление пакетной базы Linux:
# nano /etc/apt/sources.list
# apt-get update
# apt-get upgrade -y
Установим и запустим сервер SSH для более удобной удалённой работы с сервером:
# apt-get install openssh-server -y
# systemctl enable ssh
# systemctl start ssh
Установим другие утилиты, которые нам пригодятся для дальнейшей работы:
# apt-get install gdisk parted tree -y
На этом установку и первичную базовую настройку Debian Buster в нашем случае можно считать законченными.
Послеустановочная настройка загрузчика UEFI
Итак, система установлена и успешно запускается с раздела ESP (/dev/sda1) на первом диске (sda). Однако аналогичный раздел /dev/sdb1 на втором диске в данный момент пуст и с точки зрения текущих системных настроек не имеет никакого отношения к процессу загрузки операционной системы Linux.
Посмотрим, как выглядят сейчас разделы на дисках:
# lsblk -o NAME,TYPE,SIZE,FSUSED,FSUSE%,MOUNTPOINT,UUID
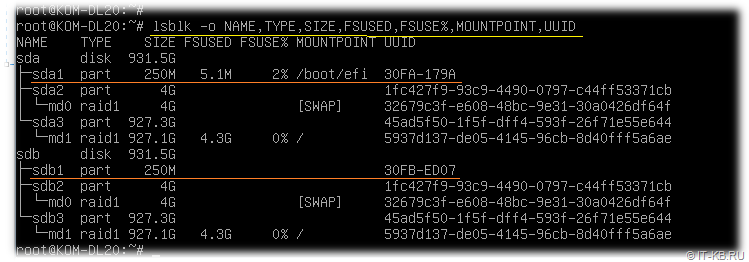
Как видим, точка монтирования с EFI-загрузчиком (каталог файловой системы /boot/efi) расположена на разделе sda1 первого диска и имеет около 5MB контента, в то время как раздел sdb1 не используется. Здесь же обратим внимание на то, что идентификаторы UUID разделов, являющихся участниками программного RAID на обоих дисках совпадают, а UUID EFI-разделов (sda1 и sdb1) различаются.
Теперь давайте посмотрим на конфигурационный файл /etс/fstab, в котором описаны правила монтирования дисковых разделов:
# cat /etc/fstab
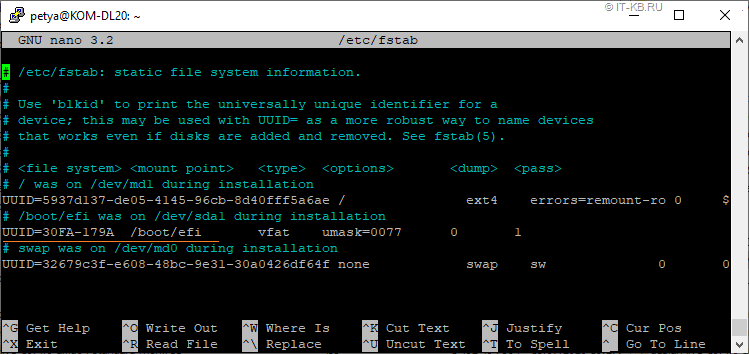
В этом файле мы увидим то, что в нашем случае каталог с файлами загрузчика EFI монтируется с FAT-раздела c UUID равным "30FA-179A", который соответствует идентификатору раздела /dev/sda1 только первого физического диска.
Кроме того, если проверить текущий порядок загрузки устройств EFI Boot manager, то мы увидим, что в нём фигурирует только запись о нашем первом физическом диске и этот диск установлен в качестве текущего источника загрузки. В этой записи есть ссылка на загрузочный файл (\EFI\debian\shimx64.efi), расположенный на первом разделе этого диска.
# efibootmgr -v
# blkid
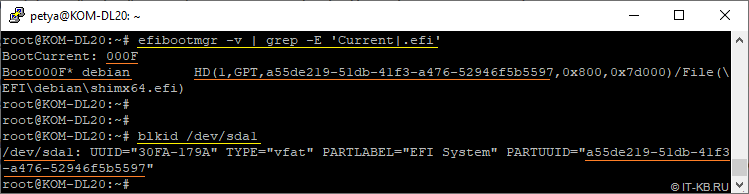
Идентификатор раздела, указанный в записи EFI Boot manager, это ни что иное, как PARTUUID раздела в контексте GPT, и очевидно, что в нашем случае здесь речь идёт только про раздел /dev/sda1.
Исходя из того, что мы видим, загрузка операционной системы будет работать только в случае, если работоспособен первый физический диск. Если же первый диск выйдет из строя, то сервер не загрузится с ESP-раздела второго физического диска. Чтобы это исправить, нам нужно сделать несколько вещей:
- Скопировать всё файловое содержимое (структуру каталогов и файлы загрузки, в числе которых shimx64.efi) с ESP-раздела первого диска (sda1) на аналогичный раздел на втором диске (sdb1);
- Изменить идентификатор UUID ESP-раздела второго диска (sdb1) таким образом, чтобы он совпадал с идентификатором ESP-раздела первого диска (sda1);
- Добавить в перечень устройств загрузки EFI Boot manager запись о втором физическом диске и его загрузочном ESP-разделе (sdb1).
Чтобы решить сразу первые две задачи, мы воспользуемся посекторным копированием всего содержимого раздела sda1 в раздел sdb1 (Внимание! Все прежние данные на разделе-получаете будут уничтожены):
# dd if=/dev/sda1 of=/dev/sdb1

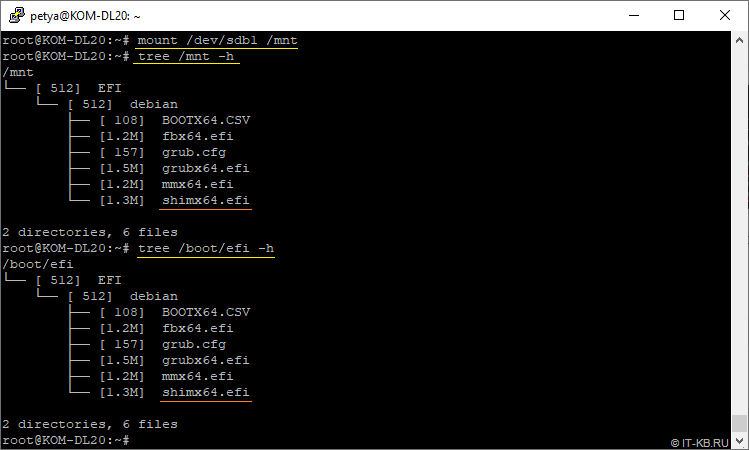
Чтобы проверить результат выполненной операции клонирования разделов, временно смонтируем раздел sdb1 в любой пустой каталог, например, в /mnt. Посмотрим на то, насколько раздел sdb1 по содержимому теперь стал похож на раздел sda1:
# mount /dev/sdb1 /mnt
# tree /mnt -h
# tree /boot/efi -h
Также убедимся в том, что теперь идентификаторы UUID ESP-разделов на обоих физических дисках идентичны:
# lsblk -o NAME,TYPE,SIZE,FSUSED,FSUSE%,MOUNTPOINT,UUID
# blkid /dev/sda1
# blkid /dev/sdb1
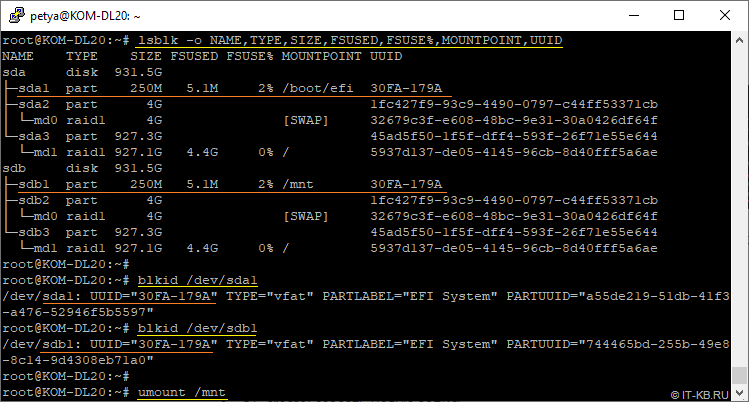
После окончания проверки не забудем отмонтировать раздел sdb1 из каталога /mnt:
# umount /mnt
Теперь осталось только отредактировать перечень устройств загрузки EFI Boot manager таким образом, чтобы там была запись не только о первом физическом диске с загрузочным ESP-разделом, но и запись о втором физическом диске с загрузочным ESP-разделом /dev/sdb1.
Для начала ещё раз проверим под каким сейчас номером запись о первом диске:
# efibootmgr -v
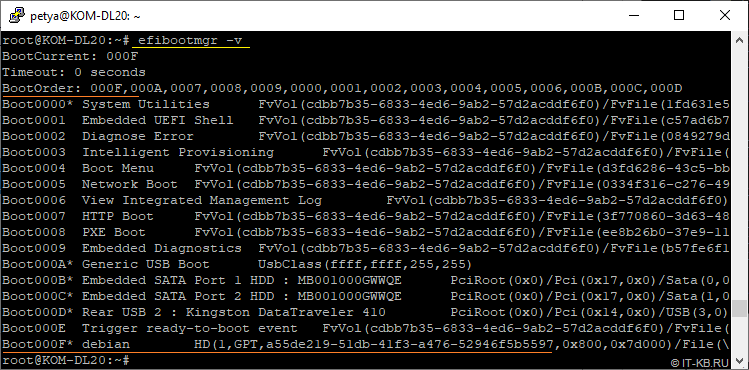
Видим, что запись о первом диске на данный момент имеет номер "000F" и в списке порядка загрузки BootOrder этот номер стоит на первом месте. Чтобы в нашей таблице EFI Boot manager всё выглядело культурно, удалим текущую запись "000F" и добавим две новые записи со схожими описаниями. При этом, если мы хотим, чтобы приоритетным диском для загрузки был первый диск, то лучше сначала добавить запись о втором диске, а затем о первом, так как в приоритет загрузки BootOrder по умолчанию первой попадает именно та запись, которая была добавлена в таблицу последней:
# efibootmgr --delete-bootnum -b 000F
# efibootmgr --create -d /dev/sdb -p 1 -L "Debian Linux EFI Partition 2" -l "\EFI\debian\shimx64.efi"
# efibootmgr --create -d /dev/sda -p 1 -L "Debian Linux EFI Partition 1" -l "\EFI\debian\shimx64.efi"
# efibootmgr -v

Как видно в нашем случае, запись о загрузочном разделе первого диска теперь имеет номер "0010", а запись второго диска "000F". При этом EFI Boot manager будет сначала пытаться выполнять загрузку с первого диска, а затем со второго.
После манипуляций с разделами и правки EFI Boot manager выполним простую перезагрузку системы, чтобы убедиться в том, что мы ничего нигде не поломали и система загружается штатным образом:
# reboot
На этом настройку системы можно считать законченной и теперь мы можем перейти к этапу проверок получившейся конфигурации.
Проверка обработки отказа дисков в RAID
Перед вводом настроенной конфигурации с программным RAID в эксплуатацию, можно провести проверку обработки отказа каждого из двух дисков по очереди, чтобы быть уверенным в том, что отказ любого из дисков не приведёт к остановке сервера и/или потере данных на дисках.
Воспользуемся тем, что наш сервер поддерживает "горячую" замену дисков, и сымитируем сбой первого диска, вытащив его из дисковой корзины прямо во время работы сервера.
После этого войдём в систему, убедимся в её штатной работе и проверим как изменилось состояние программных RAID-разделов:
# mdadm --detail /dev/md0
# mdadm --detail /dev/md1
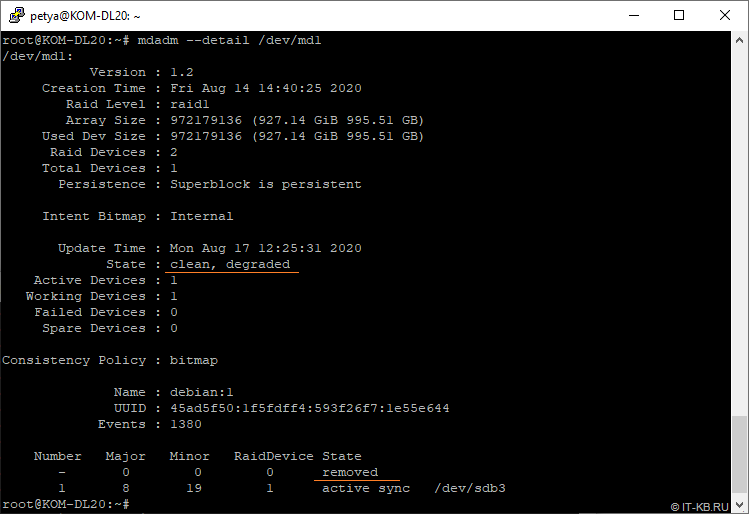
Как видим, состояние RAID-устройств изменилось на "degraded", но система при этом продолжает работать.
О произошедших в системе изменениях в mdraid можно узнать из системных логов, например, из kern.log командой типа:
# tail -n 50 -f /var/log/kern.log | grep -E 'sdb|raid'
В таком состоянии перезагрузим сервер, чтобы убедиться в том, что он успешно загрузится на втором диске.
После успешной загрузки системы снова проверим текущий статус разделов.
# cat /proc/mdstat
# lsblk -o NAME,TYPE,SIZE,FSUSED,FSUSE%,MOUNTPOINT,UUID
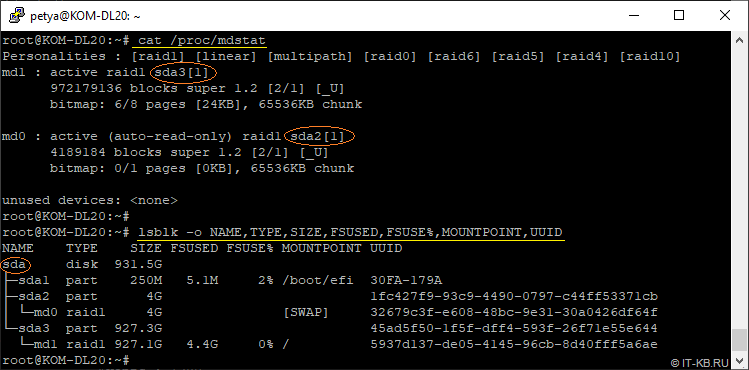
Обратите внимание на то, что теперь именование дисков и разделов изменилось. Диск, ранее считавшийся в системе, как sdb с разделами sdb1/sdb2/sdb3 теперь определён в системе, как sda с соответствующими разделами.
Далее, установим ранее извлечённый диск в дисковую корзину сервера и выполним его перезагрузку. После успешной загрузки сервера убедимся в том, что программные RAID-разделы вернулись в штатное состояние со статусом "clean".
# mdadm --detail /dev/md*
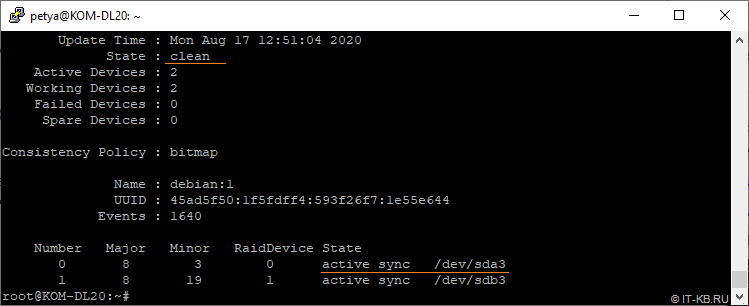
В ходе проведённых экспериментов было замечено, что RAID-раздел не всегда успешно автоматически подхватывает диск и возвращается к штатной работе. В одном таком случае подобную проблему решила повторная перезагрузка сервера и никаких дополнительных манипуляций не потребовалось. Если перезагрузка не помогает, то можно попробовать форсировано добавить диск в RAID. Например, если RAID-устройство md1 автоматически не подхватывает в работу зеркальный раздел sdb3, то можно выполнить команду следующего вида:
# mdadm --add /dev/md1 /dev/sdb3
После перехода всех разделов RAID1 в штатный решим работы, повторим эксперимент с отключением диска, но теперь уже будем отключать второй диск. При этом также следует убедиться в том, что система успешно запускается и работает на первом и единственном диске.
Таким образом, мы убедились в том, что отказ любого из дисков не приведёт к отказу работы системы или к невозможности последующей загрузки сервера с EFI-загрузчика.
Замена неисправного диска в RAID
Как правило, когда в RAID выходит из строя физический диск, то на его место устанавливается новый неразмеченный диск с аналогичными характеристиками. При возникновении такой ситуации нам потребуется выполнить ряд действий, необходимых для возобновления штатной работы RAID-разделов, а также обеспечения возможности EFI-загрузки с нового диска:
- Клонирование конфигурации дисковых разделов с рабочего диска на новый диск;
- Добавление разделов нового диска в RAID-массивы mdraid;
- Клонирование ESP-раздела на новый диск с рабочего диска;
- Корректировка загрузочной записи в EFI Boot manager
Далее рассмотрим пример всех этих действий последовательно.
После "горячей" установки нового чистого диска, теоретически можно заставить увидеть систему новый диск путём принудительного сканирования шины командами типа:
# for BUS in /sys/class/scsi_host/host*/scan; do echo "- - -" > ${BUS}; done
# for BUS in /sys/class/scsi_host/host*/scan; do echo "0 0 0" > ${BUS}; done
Однако в моём случае с сервером ProLiant DL20 у меня подобный приём не сработал и, чтобы Linux-система нормально увидела новый диск, пришлось отправлять сервер в перезагрузку.
Посмотрим текущую ситуацию по блочным устройствам в системе:
# lsblk -o NAME,TYPE,SIZE,FSUSED,FSUSE%,MOUNTPOINT,UUID
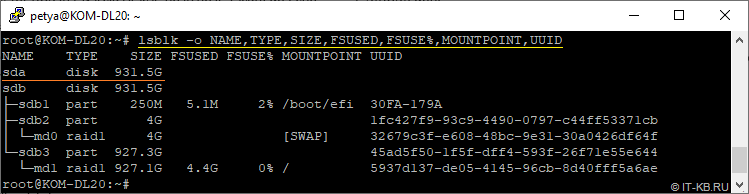
Как видим, теперь система видит новый пустой диск sda, и этот диск не имеет разделов и никак не связан с ранее настроенными RAID-устройствами md0 и md1.
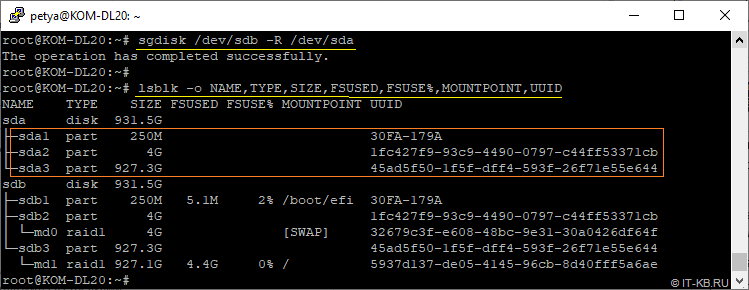
Скопируем таблицу разделов с рабочего диска sdb на новый пустой диск sda (здесь важно не перепутать источник и получатель, чтобы не потерять данные):
# sgdisk /dev/sdb -R /dev/sda
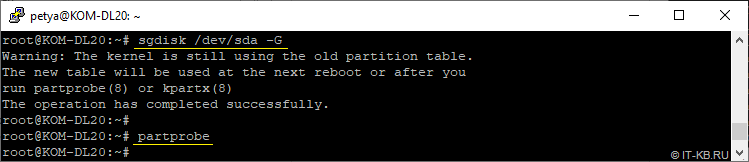
Помимо этого, выполним регенерацию PARTUUID разделов на новом диске (чтобы они не совпадали с PARTUUID разделов диска-источника):
# sgdisk /dev/sda -G
# partprobe
Теперь нам нужно добавить пустой раздел sda2 в RAID-массив md0 в качестве зеркала для работающего сейчас раздела sdb2, а пустой раздел sda3 добавить в RAID-массив md1 в качестве зеркала для работающего сейчас раздела sdb3:
# mdadm --add /dev/md0 /dev/sda2
# mdadm --add /dev/md1 /dev/sda3
После добавления разделов в RAID-массивы, автоматически запустится процесс восстановления этих массивов. Проверим статус выполнения:
# cat /proc/mdstat
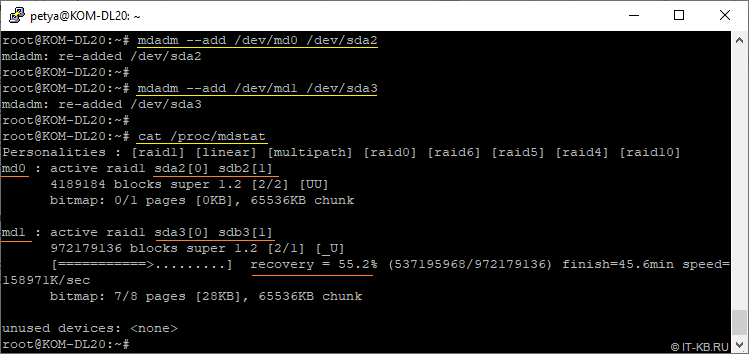
После окончания процесс восстановления, убедимся в том, что текущий статус RAID-устройств – "clean":
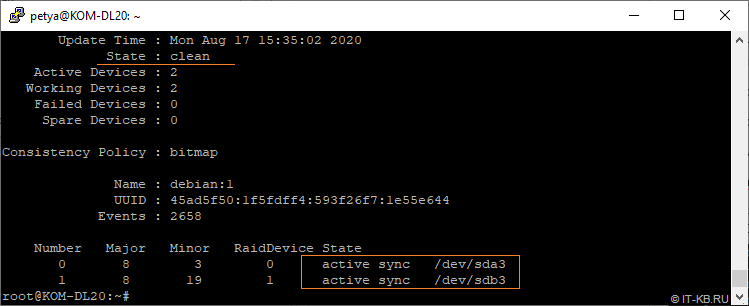
# mdadm --detail /dev/md*
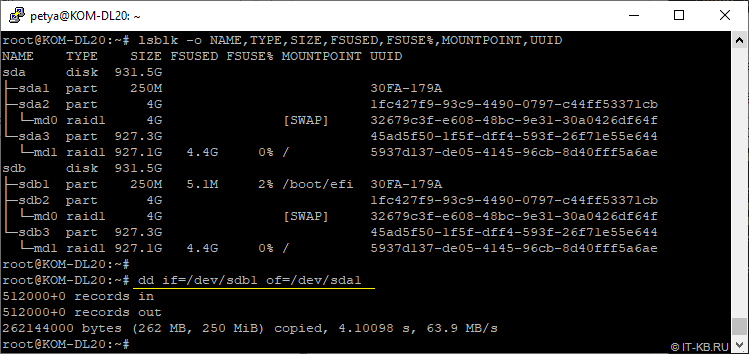
Теперь посекторно копируем все содержимое загрузочного раздела ESP c рабочего диска sdb на новый диск sda:
# dd if=/dev/sdb1 of=/dev/sda1
Напомню, что в результате мы должны получить идентичные ESP-разделы с одинаковым идентификатором раздела UUID.
Ну и наконец, переходим к последнему этапу - правке таблице загрузочных устройств в EFI Boot manager.
Давайте посмотрим, какая в нём сейчас информация:
# efibootmgr -v

Как видим, в нашем случае здесь присутствуют две записи, которые мы делал ранее. Теоретически, по условиям нашей задачи, сейчас мне нужно было бы исправить лишь одну из записей, так как мы меняли только один из дисков. Однако, пока я экспериментировал с утилитой gdisk, как-то умудрился обновить идентификаторы PARTUUID разделов ESP (sda1 и sdb1) на обоих дисках.
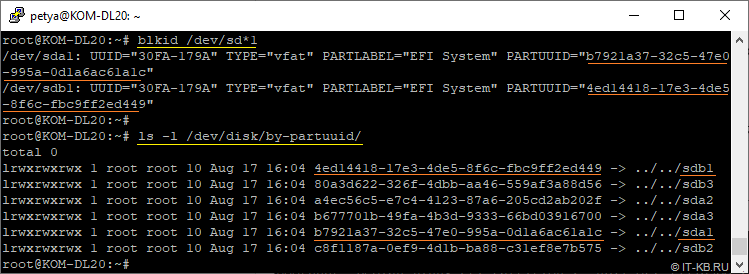
Текущие идентификаторы разделов PARTUUID можно посмотреть командами типа:
# blkid
# ls -l /dev/disk/by-partuuid/
С такими "очумелыми ручками" я просто рисковал получить незагружаемый сервер после первой же перезагрузки. Поэтому, в данном конкретном случае, мне придётся изменить информацию по обоим дискам.
Удаляем в обратном порядке старые записи (в нашем случае это записи "0010" и "000F") и сразу добавляем новые записи:
# efibootmgr --delete-bootnum -b 0010
# efibootmgr --delete-bootnum -b 000F
# efibootmgr --create -d /dev/sdb -p 1 -L "Debian Linux EFI Partition 2" -l "\EFI\debian\shimx64.efi"
# efibootmgr --create -d /dev/sda -p 1 -L "Debian Linux EFI Partition 1" -l "\EFI\debian\shimx64.efi"
# efibootmgr -v

Теперь в перечне устройств загрузки EFI Boot manager фигурируют правильные идентификаторы разделов GPT, которые используются в сервере после замены неисправного диска, и можно выполнить проверочную перезагрузку системы.
На этом процедуру полной замены неисправного диска можно считать законченной.
Мониторинг программного RAID в Linux
После запуска в работу программного RAID в Linux, нельзя обойти вниманием такой важный вопрос, как постоянный контроль состояния программных RAID-массивов. Сервер крайне желательно подключить к какой-либо системе мониторинга с поддержкой mdraid. Например, для свободно распространяемой системы мониторинга Icinga, существуют всевозможные плагины для мониторинга Linux-систем. Настройку одного из таких плагинов мы рассматривали ранее в статье Вики: Мониторинг Linux Software RAID (mdraid) в Icinga с плагином check_raid
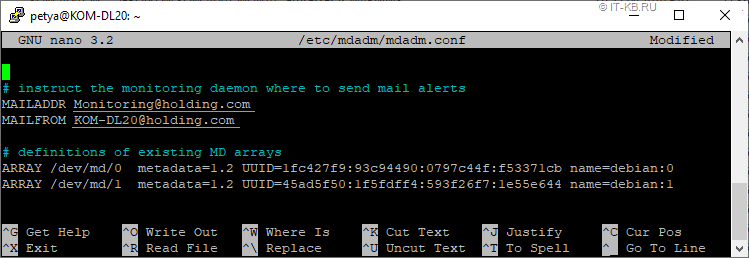
Если же под руками нет развёрнутой и функционирующей системы мониторинга подобного класса, то можно воспользоваться встроенным механизмом оповещений mdraid, который предоставляет служба "mdmonitor". Для минимальной настройки этой службы достаточно изменить email-адрес получателя (MAILADDR) и указать адрес отправителя (MAILFROM) для оповещений об изменениях в состояниях программного RAID в конфигурационном файле mdadm.conf:
# nano /etc/mdadm/mdadm.conf
После этого следует перезапустить службу "mdmonitor" и проверить её состояние:
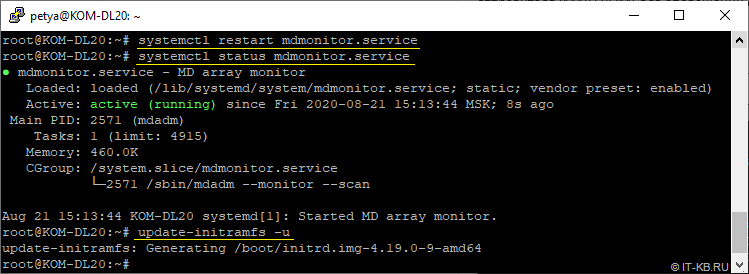
# systemctl restart mdmonitor.service
# systemctl status mdmonitor.service
Помимо этого, после правки конфигурационного файла mdadm.conf, рекомендуется выполнять команду пересборки загрузочного образа initial ramdisk, так как данный конфигурационный файл включается в состав initramfs:
# update-initramfs -u
Однако следует учесть то, что заданная для службы "mdmonitor" отсылка оповещений по электронной почте будет работать лишь в том случае, если Debian Linux настроен на пересылку почты за пределы сервера (пересылка на smarthost). Пример такой настройки описан в статье Вики "Как настроить отсылку уведомлений на внешний почтовый сервер с помощью msmtp в Debian 10 (Buster)".
Для проверки отсылки уведомлений можно воспользоваться командой:
# mdadm --monitor --scan --test --oneshot
В результате по каждому из устройств mdraid мы должны получить по отдельному письму, в котором будет присутствовать результат вывода команды "cat /proc/mdstat".
А чтобы убедиться в том, что оповещения отработают в случае возникновения проблемной ситуации, например, в случае отказа диска, можем ещё раз для проверки выдернуть из дисковой корзины сервера один из дисков. Буквально через пару минут мы должны получить от сервера письмо, сообщающее о проблеме:
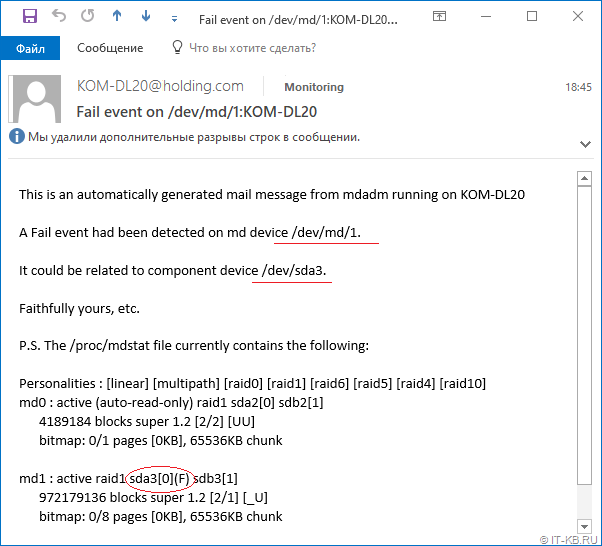
На этом базовую настройку мониторинга состояния программных RAID массивов mdraid можно считать законченной.
Дополнительные источники информации:
 RSS - Записи
RSS - Записи
Доброго дня!
Проблема такая: после установки системы по данной инструкции начинаю тестировать на отказоустойчивость физическим отключением дисков. НО если загружаюсь с диска, на котором изначально был уефи - никаких проблем, а если попытаться загрузиться со второго диска, то дальше меню биоса не пройдёшь.
Понимаю, что решение проблемы какое-то очень простое. Но самостоятельно додуматься до него не могу.
Описанная здесь последовательность проделывалась не один раз мной и моими коллегами. Где-то что-то пропустили или допустили ошибку. Манипуляций много и гадать о том, в каком месте у Вас допущена ошибка - занятие не очень интересное. Проверяйте всё с самого начала по шагам.
Спасибо за статью. Очень полезная, учитывая что в инете не много материала про зеркалирование системы именно в режиме UEFI
Но проблема как у предыдущего комментатора действительно наблюдается. Видимо он, как и я использовал данную инструкцию при установке на другую платформу (не HPE). У меня сервер DEPO. После установки Debian в EFI загрузчик BIOS добавляется пункт debian, но после удаления для проверки диска из массива этот пункт пропадает, хотя EFI область на втором диске была сделана по инструкции. И ума не приложу как это можно исправить.
Развернул аналогично, протестировал отключение дисков, не знаю как у других комментаторов, но у меня все завелось.Использовал разве что RAID 10
спасибо