![]() Имеется сервер HPE ProLiant поколения Gen10 c RAID контроллером HPE Smart Array P408i-p SR. На контроллере собран массив RAID 60 из множества накопителей большого объёма. В конфигурации контроллера активирован механизм "Spare Drive" для автоматической "горячей" подмены при отказе любого из накопителей в рабочей RAID группе. И вроде бы всё хорошо и контролируемо. Но однажды может наступить момент, когда в работающем RAID массиве один из накопителей поменяет свой статус на "Predictive Failure". То есть накопитель ещё продолжает работу, но из-за накапливающихся ошибок вероятность его отказа в обозримой перспективе становится весьма неиллюзорной.
Имеется сервер HPE ProLiant поколения Gen10 c RAID контроллером HPE Smart Array P408i-p SR. На контроллере собран массив RAID 60 из множества накопителей большого объёма. В конфигурации контроллера активирован механизм "Spare Drive" для автоматической "горячей" подмены при отказе любого из накопителей в рабочей RAID группе. И вроде бы всё хорошо и контролируемо. Но однажды может наступить момент, когда в работающем RAID массиве один из накопителей поменяет свой статус на "Predictive Failure". То есть накопитель ещё продолжает работу, но из-за накапливающихся ошибок вероятность его отказа в обозримой перспективе становится весьма неиллюзорной.
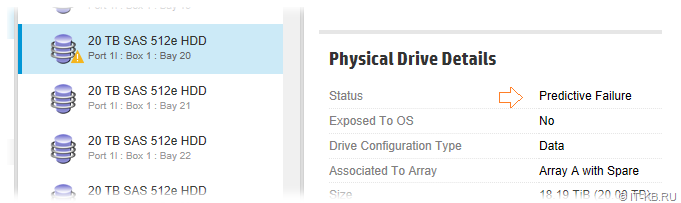
Проблема в этой ситуации заключается в том, что нет ясности в вопросе, когда же именно произойдёт этот отказ проблемного накопителя и его переход в состояние "Failed". Ведь мы понимаем, что в этот самый момент нагрузка на весь RAID массив возрастёт, так как контроллер автоматически включит в работу Spare накопитель и запустит процедуру реструктуризации массива. В такие периоды из-за возросшей нагрузки на все накопители массива повышается риск возникновения проблем с каким-либо другим накопителем. В такие моменты необходимо быть на готове к возникновению ситуаций, требующих вмешательства администратора. Но иногда некоторые обстоятельства или наши планы расходятся с требуемой готовностью к быстрому реагированию. Например, может подходить к окончанию срок гарантийного обслуживания на накопители, а в "холодный" ЗиП таких накопителей ещё не приобретено (хочется успеть попасть в гарантийную замену накопителя). Или администратор собирается в отпуск с выездом за Полярный круг, а заменить его для быстрой реакции на потенциальные проблемы некому. В такие моменты может возникнуть желание побыстрей провести замену проблемного накопителя. Но как же это можно сделать, ведь накопитель фактически ещё в работе? Можно, конечно, банально вытащить накопитель из дисковой корзины и контроллер Smart Array расценит это как внезапный отказ накопителя и запустит перестройку массива с подключением Spare накопителя. Но, как бы не был хорош Smart Array, такая ситуация - это стресс.
Есть более "мягкий" и контролируемый способ оперативного вывода из работы накопителя в состоянии "Predictive Failure". Современные контроллеры Smart Array снабжены механизмом "Predictive Spare Activation". Например, в документации к контроллеру это упоминается в документе: "HPE SR Gen10 Plus Controller User Guide - Predictive Spare Activation". И здесь следует обратить внимание на преимущества, которые по мнению производителя даёт данный механизм:
This method has the following benefits: * It is up to four times faster than a typical rebuild. * It can recover bad blocks during spare activation. * It supports all RAID levels including RAID 0.
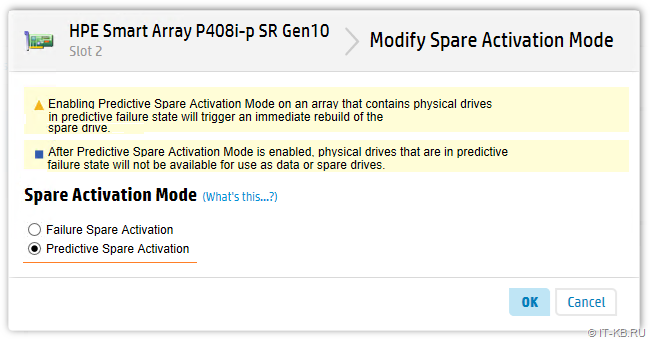
Включить этот механизм можно с помощью утилиты управления Smart Storage Administrator (SSA), используя в свойствах интересующего нас контроллера кнопку "Modify Spare Activation Mode".

В конфигурации по умолчанию используется режим "Failure Spare Activation", то есть Spare накопитель включается в работу только при условии, что какой-либо из накопителей массива окончательно перешёл в состояние "Failed". Здесь мы можем переключить контроллер на альтернативный режим "Predictive Spare Activation", при котором активация Spare накопителя происходит даже в случае, если какой-либо из накопителей массива получил статус "Predictive Failure".
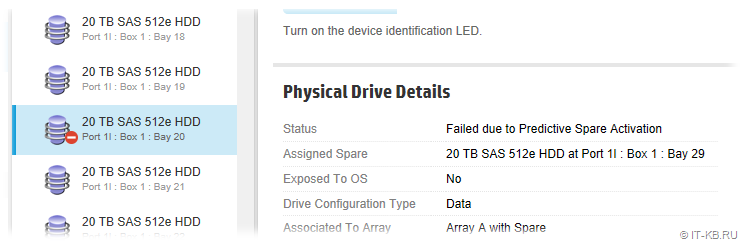
Если вы уже имеете в массиве накопитель в состоянии "Predictive Failure", то после изменения режима сразу должен активироваться Spare Disk с последующим перестроением массива, а проблемный накопитель будет переведёт в статус "Failure due to Predictive Spare Activation". Уже после этого можно физически извлечь проблемный диск из дисковой корзины сервера и заменить его на новый.
Помимо графической утилиты SSA мы можем управлять режимом Spare Activation Mode с помощью консольной утилиты "Smart Storage Administrator CLI" (ssacli). На Windows эта утилита по умолчанию устанавливается в каталог "C:\Program Files\Smart Storage Administrator\ssacli\bin\". Помимо Windows эта утилита доступна для других ОС типа Linux или VMware ESXi.
Получим перечень всех контроллеров в системе, чтобы узнать номер слота интересующего нас контроллера:
ssacli ctrl all show
HPE Smart Array P408i-p SR Gen10 in Slot 2 (sn: PFJ11JHD0D52H6)
Обратимся к контроллеру по номеру слота и получим текущее значение атрибута "spareactivationmode", а также увидим перечень допустимых вариантов этого значения:
ssacli ctrl slot=2 modify spareactivationmode=?
Available options are:
failure (current value) (default value)
predictive
Переключим контроллер в режим "Predictive Spare Activation", подтвердив запрос:
ssacli ctrl slot=2 modify spareactivationmode=predictive
Warning: Enabling Predictive Spare Activation Mode on an array that contains
physical drives in predictive failure state will trigger an immediate
rebuild of the spare drive.
Continue? (y/n) y
В случае необходимости можем вернуть контроллер в исходное состояние с режимом "Failure Spare Activation":
ssacli ctrl slot=2 modify spareactivationmode=failure
Warning: Disabling Predictive Spare Activation Mode will remove all spare
drive(s) from arrays that contain only RAID 0 logical drives. Any
spare rebuilds currently under way will complete and the predictive
failure drive will be put offline, even after Predictive Spare
Activation Mode is disabled.
Continue? (y/n) y
Поразмыслив на тему выбора оптимального режима, я пришёл к выводу, что лучше оставить всё как есть в конфигурации по умолчанию. То есть для постоянной эксплуатации использовать режим "Failure Spare Activation", а режим "Predictive Spare Activation" включать лишь временно в исключительных ситуациях, когда нужно оперативно вывести из работы накопитель в состоянии "Predictive Failure".
 RSS - Записи
RSS - Записи
Добавить комментарий