![]() После развёртывания и недлительной эксплуатации выделенного сервера с SharePoint Workflow Manager, подключенного к SharePoint Server 2019, на базе ОС Windows Server 2022 столкнулись с проблемой переполнения системного диска логами Service Fabric. Обнаружилось множество накопившихся файлов *.etl, *.trace и *.blg в разных подкаталогах каталога C:\ProgramData\Microsoft Service Fabric\Log.
После развёртывания и недлительной эксплуатации выделенного сервера с SharePoint Workflow Manager, подключенного к SharePoint Server 2019, на базе ОС Windows Server 2022 столкнулись с проблемой переполнения системного диска логами Service Fabric. Обнаружилось множество накопившихся файлов *.etl, *.trace и *.blg в разных подкаталогах каталога C:\ProgramData\Microsoft Service Fabric\Log.
После изучения опыта борьбы коллег с подобным явлением на разных интернет ресурсах стала вырисовываться картина того, что проблема с неконтролируемо накапливаемыми трейс-логами известна со времён AppFabric и плавно перекочевала в Azure Service Fabric.
В нашем случае в оснастке управления компьютером в разделе "Perfomance\Data Collector Sets" был обнаружен набор сборщиков данных производительности "FabricCounters", порождающий множество файлов *.blg в подкаталоге \Log\PerformanceCountersBinary
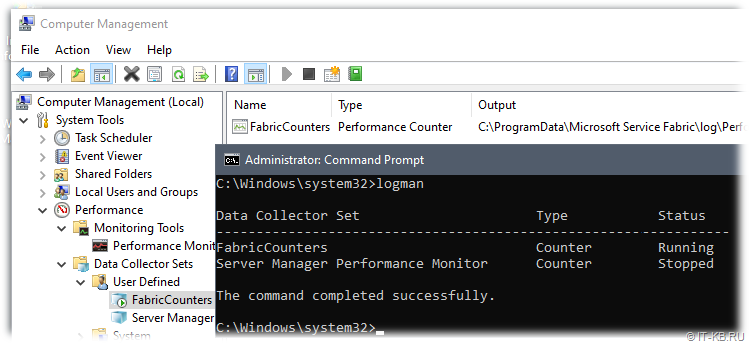
Остановка этого набора ситуацию по существу не меняла, так как после очередной перезагрузки сервера набор снова запускался.
Помимо этого в разделе "Event Trace Sessions" мы обнаружили ещё 5 автоматически запускаемых трейсеров:
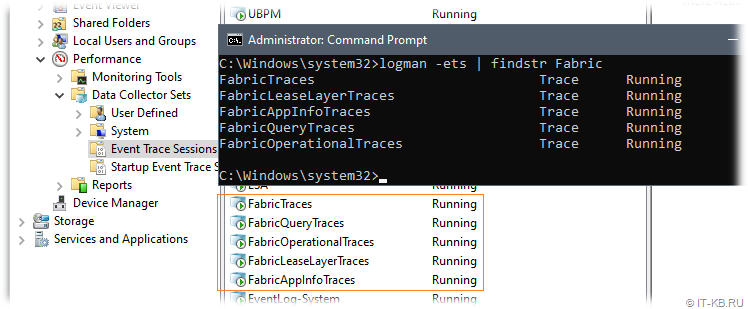
Все они пишут логи в разные подкаталоги ранее упомянутого каталога C:\ProgramData\Microsoft Service Fabric\Log. Особенная активность наблюдается в подкаталоге \Log\Traces, размер которого в нашем случае достиг нескольких десятков гигабайт. Попытки остановки или даже удаления этих трейсеров через logman приводили к их повторному появлению и запуску в течение нескольких последующих минут. Не помог изменить ситуацию также и файл StopTracing.cmd из каталога C:\Program Files\Microsoft Service Fabric\bin\Fabric\Fabric.Code, который по сути также безрезультатно дёргает тот же logman.
В планировщике заданий Windows Task Scheduler обнаружилось задание "FabricCounters" в разделе \Microsoft\Windows\PLA, которое, как я понял, и вызывает запуск одноимённого сборщика данных производительности.
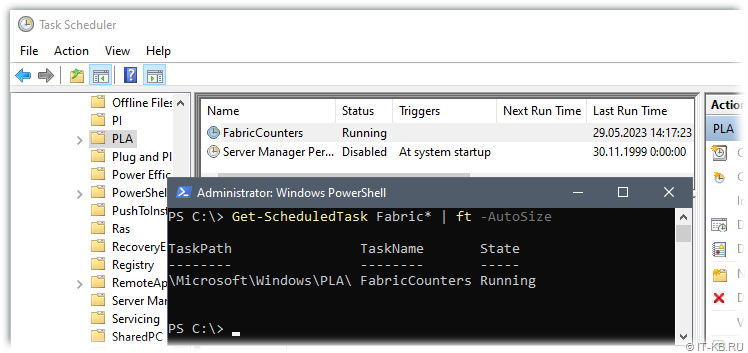
Попытки отключения или даже удаления этого задания приводили к повторному появлению и запуску задания после следующей перезагрузки системы.
В общем на текущий момент времени, для меня так и осталось загадкой то, как можно изменить поведение неубиваемого механизма логирования Service Fabric, и, судя по ветке "How do I disable FabricCounters and Fabric Event Trace Sessions?", я в этом вопросе не одинок.
А для того, чтобы в дальнейшем избежать ситуаций с переполнением диска на сервере с Service Fabric, как минимум, можно настроить регулярное удаление старых лог-файлов с помощью PowerShell.
Пример простого скрипта ServiceFabricTracesCleaning.ps1, удаляющего старые файлы:
$CurrentDate = Get-Date
$DatetoDelete = $CurrentDate.AddDays(-1)
$FolderstoClean = @(
"C:\ProgramData\Microsoft Service Fabric\Log\AppInstanceData\Etl"
"C:\ProgramData\Microsoft Service Fabric\Log\OperationalTraces"
"C:\ProgramData\Microsoft Service Fabric\Log\PerformanceCountersBinary"
"C:\ProgramData\Microsoft Service Fabric\Log\QueryTraces"
"C:\ProgramData\Microsoft Service Fabric\Log\Traces"
)
ForEach ($Folder in $FolderstoClean) {
Get-ChildItem $Folder | Where-Object { $_.LastWriteTime -lt $DatetoDelete } | Remove-Item
}
Скрипт добавляем в задание планировщика Windows Task Scheduler с выполнением в следующем виде:
powershell.exe -NoProfile -command "C:\TaskScheduler\ServiceFabricTracesCleaning.ps1"
Расписание запуска настраиваем, например, раз в сутки.
Дополнительные мысли и идеи по "дрессировке" механизма логирования Service Fabric принимаются и приветствуются ![]()
 RSS - Записи
RSS - Записи
В Skype for Business 2015 подобная проблема решалась установкой в конфиге ClusterManifest.Xml.Template лимита на хранение трейсов:
https://itgala.xyz/skype-for-business-2015-limit-fabric-tracing-logs-growth/
Решением проблемы я считаю деактивацию механизма записи трейсов, а не удаление старых трейсов. Удаление старых трейсов мы итак по сути накостылили с помошью PS.
Зачем писать отладочную информацию на постоянной основе, если она нам не нужна и не интересна. Ничего кроме излишней нагрузки на файловую систему и увеличения объёма резервных копий виртуального сервера нам это не даёт.