![]() На одной из отдалённых площадок из-за проблем с входящим в серверное помещение электропитанием столкнулись с нештатной ситуацией в работе СХД HPE MSA 2052. На протяжении нескольких ночных часов входящее напряжение судорожно отключалось и снова включалось множество раз. СХД при этом, как и положено, разными блоками питания была запитана от разных ИБП, каждый их которых после первого длительного отключения питания честно отработал до полного истощения батарей. Последующие кратковременные подачи электричества приводили к такому же кратковременному включению и последующему повторному отключению всего оборудования в серверной (в том числе и СХД), так как истощённые при первом длительном отключении ИБП ещё не успели набрать заряд батарей.
На одной из отдалённых площадок из-за проблем с входящим в серверное помещение электропитанием столкнулись с нештатной ситуацией в работе СХД HPE MSA 2052. На протяжении нескольких ночных часов входящее напряжение судорожно отключалось и снова включалось множество раз. СХД при этом, как и положено, разными блоками питания была запитана от разных ИБП, каждый их которых после первого длительного отключения питания честно отработал до полного истощения батарей. Последующие кратковременные подачи электричества приводили к такому же кратковременному включению и последующему повторному отключению всего оборудования в серверной (в том числе и СХД), так как истощённые при первом длительном отключении ИБП ещё не успели набрать заряд батарей.
Судя по логам СХД, уже под утро, после очередного такого выключения/включения дисковый пул на контроллере "А" перешёл в состояние Fault с ошибкой "The virtual pool is offline due to unreadable metadata (BLPT error)".
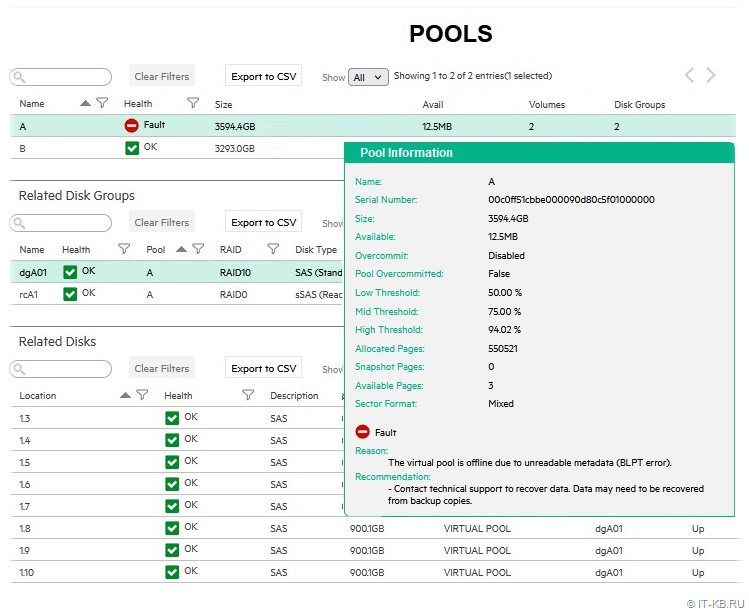
При этом все дисковые группы и диски, входящие в пул, отображали свой статус как "ОК".
В конечном результате доступ к презентованным LUN-ам из пула "A" перестал работать штатным образом. То есть серверы, которым была презентована дисковая ёмкость, видели LUN-ы, но работать с ними не могли (ни на чтение, ни на запись).
Понимая то, что имеющийся у нас на данную СХД уровень тех.поддержки HPE предполагает реакцию по типу NBD (Next Business Day), и имея некий опыт работы с таким типом поддержки, для ускорения процесса восстановления доступа к данным мы решили самостоятельно пересобрать дисковый пул и восстановить данные из последней резервной копии.
Однако, как оказалось, проблемный пул в текущем его состоянии СХД не позволяет нам удалить через штатные инструменты управления в веб-консоли и аналогичные команды в SSH-сессии. И поэтому нам всё-таки пришлось открыть обращение в тех.поддержку HPE для того, чтобы понять как нам вернуть в работу диски проблемного пула "А".
Тем не менее, время шло и доступ к данным нужно было восстанавливать в оперативном режиме. В течение нескольких последующих часов мы собрали из имеющихся у нас в резерве физических дисков дополнительный дисковый пул "B" и восстановили туда данные из резервной копии. Поэтому, когда дело дошло до общения с инженером HPE (после прелюдий со сбором логов СХД и работы с первой линией ТП), для нас вопрос восстановления данных на пуле "А" не стоял уже в принципе. Единственной нашей задачей было корректное высвобождение дисков из пула "А" и пересоздание этого пула (соответственно, с утерей всех данных в пуле).
В итоге выяснилось, что для возможности удаления проблемного пула, необходимо дать по сути всего одну недокументированную (в публично доступной документации) команду, что и было сделано инженером HPE под нашим пристальным наблюдением. В результате проблемный пул был успешно разобран и у нас появилась возможность повторного пересоздания пула.
Далее приведу последовательность действий, которую потребуется выполнить для неудаляемого пула, чтобы его таки удалить. Разумеется, использовать подобные действия вы можете только на свой страх и риск, особенно, если СХД всё ещё находится на тех.поддержке.
Удаляем проблемный пул
Подключаемся к контроллеру СХД по SSH с административной учётной записью созданного ранее пользователя, например "Admin".
Создаём нового пользователя c именем "HPE" и набором ролей "diagnostic,manage,monitor":
# create user roles diagnostic,manage,monitor HPE
Enter new password: ********
Re-enter new password: ********
Success: Command completed successfully. (HPE) - The new user was created. (2021-11-09 15:44:41)
Проверяем список пользователей и убеждаемся в наличии созданного пользователя с необходимым набором ролей:
# show users Username Roles User Type User Locale WBI CLI FTP SMI-S SNMP ... --------------------------------------------------------------------------------------------------- Admin manage,standard,monitor Standard English x x x x HPE diagnostic,manage,monitor Standard English x x monitor standard,monitor Standard English x x x --------------------------------------------------------------------------------------------------- Success: Command completed successfully. (2021-11-09 09:18:41)
Завершаем текущую сессию административного пользователя (в нашем примере "Admin") и создаём новую SSH-сессию от имени вновь созданного пользователя "HPE".
Выполняем получение привилегии на форсированное удаление пула (та самая волшебная команда):
# set advanced-settings HPE-delete-pool-access enabled
Virtual pools and disk groups must be removed in a specific order to maintain data integrity. Enabling HPE-delete-pool-access will bypass any system checks generally made to preserve this order. Deleting pools or disk groups with this setting enabled may cause irreparable damage to the pool and any user data therein.
Are you sure you want to continue? (y/n) y
Info: The HPE-delete-pool-access setting will remain enabled for approximately 15 minutes, after which time the setting will automatically be disabled. When the system has been properly cleaned up, both controllers should be restarted (individually, to avoid data unavailability) using the command: restart sc [a|b].
Success: Command completed successfully. (2021-11-09 09:21:17)
Как видим из сообщения, полученная опасная привилегия будет действовать в течение 15 минут, после чего автоматически будет выключена.
Проверим действующий набор привилегий и убедимся в том, что там есть соответствующая позиция:
# show advanced-settings
Disk Group Background Scrub: Enabled
Disk Group Background Scrub Interval: 24
Partner Firmware Upgrade: Enabled
Utility Priority: High
SMART: Enabled
Dynamic Spare Configuration: Enabled
Enclosure Polling Rate: 5
Host Control of Caching: Disabled
Sync Cache Mode: Immediate
Missing LUN Response: Not Ready
Controller Failure: Disabled
Supercap Failure: Enabled
CompactFlash Failure: Enabled
Power Supply Failure: Disabled
Fan Failure: Disabled
Temperature Exceeded: Disabled
Partner Notify: Disabled
Auto Write Back: Enabled
Inactive Drive Spin Down: Disabled
Inactive Drive Spin Down Delay: 0
Disk Background Scrub: Enabled
Managed Logs: Disabled
Single Controller Mode: Disabled
Auto Stall Recovery: Enabled
HPE Delete Pool Access: Enabled
Restart on CAPI Fail: Enabled
Large Pools: Disabled
Success: Command completed successfully. (2021-11-09 09:21:35)
На всякий случай ещё раз проверяем состояние контроллеров СХД и убеждаемся в их штатном функционировании:
# show controllers Controllers ----------- Controller ID: A ... Status: Operational Failed Over to This Controller: No Fail Over Reason: Not applicable Multi-core: Disabled Health: OK Health Reason: Health Recommendation: Position: Top Phy Isolation: Enabled Controller Redundancy Mode: Active-Active ULP Controller Redundancy Status: Redundant Controllers ----------- Controller ID: B ... Status: Operational Failed Over to This Controller: No Fail Over Reason: Not applicable Multi-core: Disabled Health: OK Health Reason: Health Recommendation: Position: Bottom Phy Isolation: Enabled Controller Redundancy Mode: Active-Active ULP Controller Redundancy Status: Redundant Success: Command completed successfully. (2021-11-09 09:19:22)
Проверяем текущее состояние дисковых пулов (видим, что пул "А" находится в состоянии ошибки):
# show pools
Name Serial Number Blocksize Total Size Avail Snap Size OverCommit Disk Groups Volumes Low Thresh Mid Thresh High Thresh Sec Fmt Health Reason Action
--------------------------------------------------------------------------------------------------
A 00c0ff51cbbe000090d80c5f01000000 512 3594.4GB 12.5MB 0B Disabled 2 2 50.00 % 75.00 % 94.02 % Mixed Fault The virtual pool is offline due to unreadable metadata (BLPT error). - Contact technical support to recover data. Data may need to be recovered from backup copies.
B 00c0ff51cf2a000009ee7f6101000000 512 3293.0GB 1062.7GB 0B Enabled 1 2 50.00 % 75.00 % 93.47 % 512n OK
---------------------------------------------------------------------------------------------------
Success: Command completed successfully. (2021-11-09 09:21:43)
Выполняем команду форсированного удаления проблемного пула "А":
# delete pools A
All data on pool A will be deleted.
Do you want to continue? (y/n) y
Info: The virtual pool was deleted. (A)
Success: Command completed successfully. (2021-11-09 09:24:03)
Ещё раз выполняем листинг пулов, чтобы удостовериться в том, что что пул "А" удалён:
# show pools
Name Serial Number Blocksize Total Size Avail Snap Size OverCommit Disk Groups Volumes Low Thresh Mid Thresh High Thresh Sec Fmt Health Reason Action
---------------------------------------------------------------------------------------------------
B 00c0ff51cf2a000009ee7f6101000000 512 3293.0GB 1062.7GB 0B Enabled 1 2 50.00 % 75.00 % 93.47 % 512n OK
---------------------------------------------------------------------------------------------------
Success: Command completed successfully. (2021-11-09 09:24:09)
На всякий случай проверим всё ли хорошо с состоянием дисковых групп, которые в нашем случае имеются во втором живом пуле "В":
# show disk-groups
Name Size Free Pool Tier % of Pool Own RAID Disks Status Current Job Job% Sec Fmt Health Reason Action
---------------------------------------------------------------------------------------------------
dgB01 3293.0GB 1062.7GB B Standard 100 B RAID5 12 FTOL 512n OK
---------------------------------------------------------------------------------------------------
Success: Command completed successfully. (2021-11-09 09:24:20)
Проверяем состояние дисков. Убеждаемся в том, что диски, ранее принадлежавшие дисковым группам в удалённом проблемном пуле, теперь не относятся ни к какой из дисковых групп.
# show disks
Location Serial Number Vendor Rev Description Usage Jobs Speed (kr/min) Size Sec Fmt Disk Group Pool Tier Health
---------------------------------------------------------------------------------------------------
1.1 301... HP HPD7 SSD SAS AVAIL 0 800.1GB 512e Read Cache OK
1.2 301... HP HPD7 SSD SAS AVAIL 0 800.1GB 512e Read Cache OK
1.3 20L... HP HPD4 SAS AVAIL 15 900.1GB 512n Standard OK
1.4 20L... HP HPD4 SAS AVAIL 15 900.1GB 512n Standard OK
...
1.11 PMG... HP HPD9 SAS VIRTUAL POOL 10 300.0GB 512n dgB01 B Standard OK
1.12 246... HP HPD0 SAS VIRTUAL POOL 10 300.0GB 512n dgB01 B Standard OK
1.13 S0K... HP HPD5 SAS VIRTUAL POOL 10 300.0GB 512n dgB01 B Standard OK
...
---------------------------------------------------------------------------------------------------
Info: * Rates may vary. This is normal behavior. (2021-11-09 09:24:46)
Success: Command completed successfully. (2021-11-09 09:24:46)
Задача по удалению проблемного пула выполнена. Теперь можно завершить сессию пользователя "HPE" и снова вернуться в сессию пользователя "Admin", из которой уже удалить пользователя "HPE":
# delete user HPE
Are you sure you want to delete user HPE? (y/n) y
Success: Command completed successfully. (2021-11-09 16:29:55)
В заключении хочется обозначить мораль исходной истории, которую в сухом остатке можно свести к тому, что на любую железку, казалось бы, Enterprise-уровня можно совершенно неожиданно словить такую ситуацию, когда всё может оказаться очень и очень грустно. Поэтому крайне важно своевременно и на регулярной основе уделять должное внимание задачам резервного копирования данных.
Дополнительные источники информации:
 RSS - Записи
RSS - Записи
>отработал до полного истощения батарей
Кхм, даже дешевые упсы имеют порог по заряду батареи и отключатся, не дав _полностью_ ей разрядится.
Плюс приличные упсы не включатся, пока не зарядят батареи до приемлемого уровня. Также можно настроить временной лаг на включение после появления питания в сети.
С таким успехом лучше truenas scale развернуть на zfs, чем проприетарщину от hp пользовать.
"Enterprise-уровня можно совершенно неожиданно словить такую ситуацию," ложные выводы на базе ложного Ынтерпрайза. Такой хе.ни у нормальных производителей не встречал
У нас была подобная проблема, правда возникшая из за недоступности дополнительной корзины, SAS кабели не до конца воткнули после переезда, включили и получили такую проблему на пуле куда входили диски со 2й корзины. Нам с такой же ошибкой помогла более простая операция - полностью выключить питание на массиве и доп.корзине, затем включить доп.корзину, подождать несколько минут, и включить основной массив, после этого ошибка пропала.
У нас такая же проблема, но хранилка MSA1050. Команду set advanced-settings HPE-delete-pool-access enabled уже не признаёт
show advanced-settings не показывает ничего похожего на "HPE Delete Pool Access" ?
В сети можно найти информацию, что от версии к версии прошивки эти недокументированные опции могут меняться.
Если старая версия прошивки, то можно попробовать ещё такой вариант:
set advanced-settings virtual-pool-delete-override on