![]() Продолжая ранее начатый квест по взбадриванию двух-контроллерной СХД HP 3PAR StoreServ 7200, напомню, что получена эта система в нашем случае была с небольшой частью дисковой ёмкости, которая была помечена как неисправная. В этой заметке мы поговорим о том, как выяснить то, к каким дисковым накопителям в СХД относится неисправная ёмкость и что в такой ситуации можно сделать.
Продолжая ранее начатый квест по взбадриванию двух-контроллерной СХД HP 3PAR StoreServ 7200, напомню, что получена эта система в нашем случае была с небольшой частью дисковой ёмкости, которая была помечена как неисправная. В этой заметке мы поговорим о том, как выяснить то, к каким дисковым накопителям в СХД относится неисправная ёмкость и что в такой ситуации можно сделать.
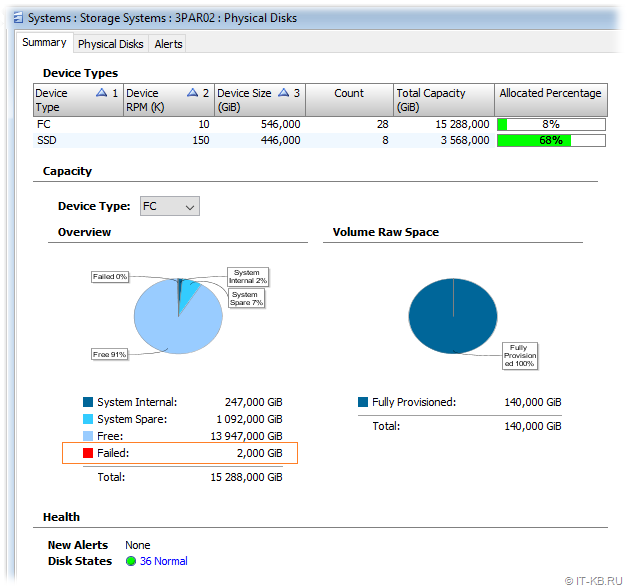
Итак, при поверхностном осмотре состояния компонент СХД в консоли управления HP 3PAR Management Console было обнаружено 2GiB ёмкости в состоянии "Failed".
А насколько нам известно, в 3PAR OS 3.2/3.3 на самом нижнем уровне СХД оперирует физическими блоками (chanklets) размером 1GiB. Получается, что у нас есть 2 неисправных чанклета и нам в первую очередь потребуется выяснить, к каким дисковым накопителям относятся эти блоки. Для этого подключимся по SSH к СХД от имени учётной записи "3paradm" и выполним команду вывода информации о всех проблемных чанклетах:
3PAR02 cli% showpdch -fail Pdid Chnk LdName LdCh State Usage Media Sp Cl From To 3 239 ---- --- none available failed N N --- --- 12 296 ---- --- none available failed N N --- --- ----------------------------------------------------------- Total chunklets: 2
Как видим, проблемные чанклеты физически находятся на дисках 3 и 12.
Теперь возникают резонные вопросы – насколько это опасно для данных и что делать с дисками, имеющими проблемные чанклеты?
Наличие некоторого количества неисправных чанклетов в 3PAR на самом деле не является для СХД какой-то критической проблемой и такие чанклеты попросту не будут использоваться для размещения данных. По некоторой неофициальной информации дисковый накопитель в актуальных версиях 3PAR OS будет считаться работоспособным, пока на нём не будет зафиксировано 10 неисправных чанклетов (или 6 чанклетов для более старых версий 3PAR OS). При превышении указанной границы диск помечается как неисправный и обязательно должен быть заменён.
Процедуру стандартной замены неисправного накопителя с помощью утилиты "servicemag" мы уже рассматривали ранее в заметке Вики IT-KB - Замена неисправного физического диска в СХД HP 3PAR 7200.
Можно предположить, что алгоритмы 3PAR OS помечают чанклет, как неисправный, в результате безуспешной попытки операций чтения/записи. Но что, если такая ошибка была вызвана не реальной проблемой носителя, а какой-то временной коллизией в работе микрокода контроллера накопителя/контроллеров дисковой корзины/контроллеров плат ввода-вывода или даже микрокода самой 3PAR OS? Вероятность этого может быть мала и не всегда очевидна, но всё же не стоит её сбрасывать со счетов.
Надо признать, что в нашем примере СХД не содержит полезных данных и после использования ёмкости ранее под одну задачу, мы готовим эту ёмкость под использование в другой задаче с полным перестроением CPG и Virtual Volumes. Поэтому, на данном этапе хочется дать двум дискам с единственным проблемным чанклетом "второй шанс", понимая при этом и то, что перспектива повторения ситуации с появлением битых чанков (если диски действительно "устали") вполне реальна.
Сложность этой затеи заключается в том, что разметка физической ёмкости накопителей на чанклеты штатным образом выполнятся лишь на этапе первичной инициализации СХД. И если в работающей системе на диске появился неисправный чанклет, то он будет болтаться на нём до логического завершения жизненного цикла диска в составе СХД. То есть, например, у нас не получится схитрить и обмануть 3PAR OS, просто выведя диск из работы и введя вновь в работу с помощью выше упомянутой утилиты "servicemag" (как при ранее упомянутой штатной замене диска). Это связано с тем, что СХД продолжает "помнить" об этом конкретном накопителе и при повторном вводе его в работу снова покажет на нём неисправный чанклет. Однако, если мы подумаем о том, как СХД вводит в работу новый накопитель (которого ранее ещё не было в системе), то становится очевидно, что на этапе ввода диска в работу происходит его форматирование и разбивка на "свежие" чанки. Получается, что для реализации нашей затеи нам просто нужно заставить 3PAR OS "забыть" о двух интересующих нас дисках.
Первое, что нам нужно сделать, – запретить СХД размещение данных на диске, который хотим полностью исключить из работы. Сначала сделаем это для первого диска с ID 3:
3PAR02 cli% setpd ldalloc off 3
Убеждаемся в том, что диск 3 перешёл в состояние "degraded" с признаком запрета размещения на нём данных:
3PAR02 cli% showpd -s 3 Id CagePos Type -State-- -------Detailed_State-------- -SedState-- 3 0:3:0 FC degraded not_available_for_allocations not_capable ------------------------------------------------------------------ 1 total
Освобождаем все данные с диска 3, перенося их на другие доступные диски СХД с помощью команды "movepdtospare":
3PAR02 cli% movepdtospare -f -vacate -nowait 3
Move -State- ----Detailed_State----
3:526-18:0 normal ch_move_pending,normal
3:527-18:1 normal ch_move_pending,normal
3:528-19:2 normal ch_move_pending,normal
3:535-18:3 normal ch_move_pending,normal
3:536-18:4 normal ch_move_pending,normal
3:537-18:5 normal ch_move_pending,normal
3:538-18:6 normal ch_move_pending,normal
3:539-18:7 normal ch_move_pending,normal
3:540-18:8 normal ch_move_pending,normal
3:541-18:9 normal ch_move_pending,normal
3:542-18:10 normal ch_move_pending,normal
3:543-18:11 normal ch_move_pending,normal
3:544-18:12 normal ch_move_pending,normal
3:545-18:13 normal ch_move_pending,normal
Процесс переноса данных чанклетов на другие накопители может занять некоторое время. Отследить текущий статус переноса данных можно командой:
3PAR02 cli% showpdch -mov Pdid Chnk LdName LdCh State Usage Media Sp Cl From To 3 526 pdsld0.1 7 normal relsrc valid N N --- 18:0 3 527 pdsld0.1 1 normal relsrc valid N N --- 18:1 3 535 .srdata.usr.0 57 normal relsrc valid N N --- 18:3 3 536 .srdata.usr.0 51 normal relsrc valid N N --- 18:4 3 537 .srdata.usr.0 44 normal relsrc valid N N --- 18:5 18 0 pdsld0.1 7 normal reltgt valid N N 3:526 --- 18 1 pdsld0.1 1 normal reltgt valid N N 3:527 --- 18 3 .srdata.usr.0 57 normal reltgt valid N N 3:535 --- 18 4 .srdata.usr.0 51 normal reltgt valid N N 3:536 --- 18 5 .srdata.usr.0 44 normal reltgt valid N N 3:537 --- ----------------------------------------------------------------- Total chunklets: 10
Как видим, в нашем примере на текущий момент времени выполняется перенос данных с диска 3 на диск 18. Повторяем последнюю команду, чтобы получать обновлённую информацию о статусе переноса и дожидаемся, когда перенос данных будет завершён полностью:
3PAR02 cli% showpdch -mov No chunklet information available.
Данные с нашего 3 диска "уехали", теперь осталось исключить диск из пула размещения резервных чанклетов (Spare chunklets). Для начала проверим то, сколько на данный момент времени мы имеем на диске чанклетов, выступающих в роли резервных:
3PAR02 cli% showpdch -spr 3 Pdid Chnk LdName LdCh State Usage Media Sp Cl From To 3 493 ---- --- none unavailable valid Y Y --- --- 3 494 ---- --- none unavailable valid Y Y --- --- ... вывод усечён .... 3 533 ---- --- none unavailable valid Y Y --- --- 3 534 ---- --- none unavailable valid Y Y --- --- ------------------------------------------------------------ Total chunklets: 39
Как видим, на диске есть 39 резервных чанклетов. Удалим их командой "removespare". В этой команде после ID диска указывается ключ ":a", что означает директиву удаления всех spare-чанков:
3PAR02 cli% removespare 3:a Are you sure you want to remove spares? select q=quit y=yes n=no: y 39 spares removed
Проверяем результат и убеждаемся в том, что с точки зрения СХД диск теперь не содержит резервных чанклетов:
3PAR02 cli% showpdch -spr 3 No chunklet information available.
Ну и, наконец, с помощью команды "dismisspd" полностью выводим диск из работы:
3PAR02 cli% dismisspd 3
Перечисленными выше командами мы вывели диск с ID 3 из работы.
Теперь можно повторить всю туже последовательность команд для второго диска с ID 12:
3PAR02 cli% setpd ldalloc off 12 ... 3PAR02 cli% movepdtospare -f -vacate -nowait 12 ... 3PAR02 cli% removespare 12:a ... 3PAR02 cli% dismisspd 12
Только теперь мы можем спокойно извлечь диски из дисковой корзины с пониманием того, что СХД "забыла" про эти диски.
На данном этапе мы ещё можем одуматься и установить на место извлечённых дисков новые сменные диски ![]() … Но если таких дисков нет и затея повторно использовать эти же диски ещё не оставила "воспалённый разум", то вставляем эти диски снова в корзину. При этом (если диски одинаковые по ёмкости и типу) даже можем поменять эти диски местами.
… Но если таких дисков нет и затея повторно использовать эти же диски ещё не оставила "воспалённый разум", то вставляем эти диски снова в корзину. При этом (если диски одинаковые по ёмкости и типу) даже можем поменять эти диски местами.
После установки дисков наблюдаем за событиями, которые появляются в логе СХД. Например, чтобы посмотреть логи за последние 20 минут, выполнима команду следующего вида:
3PAR02 cli% showeventlog -min 20 -oneline ... Informational Disk state change sw_pd:3 pd 3 wwn 5000C50017B90D45 changed state from new to valid because disk was admitted successfully. Informational Disk state change hw_disk:5000C50017B90D45 pd wwn 5000C50017B90D45 changed state from new to valid because disk was admitted successfully. Informational Object added sw_pd:3 Physical Disk 3 added Informational Object added hw_disk:5000C50017B90D45 Disk 5000C50017B90D45 added ... Informational Disk state change sw_pd:12 pd 12 wwn 5000C50017D0A54B changed state from new to valid because disk was admitted successfully. Informational Disk state change hw_disk:5000C50017D0A54B pd wwn 5000C50017D0A54B changed state from new to valid because disk was admitted successfully. Informational Object added sw_pd:12 Physical Disk 12 added Informational Object added hw_disk:5000C50017D0A54B Disk 5000C50017D0A54B added ...
Как видим, система приняла диски как новые, проверила их на совместимость по версии микрокода и через мгновенье поменяла их статус с new на valid. При этом диски автоматически включились в работу и запустился фоновый процесс переноса части данных с других рабочих дисков. Заглянем в консоль HP 3PAR Management Console и проверим результат.
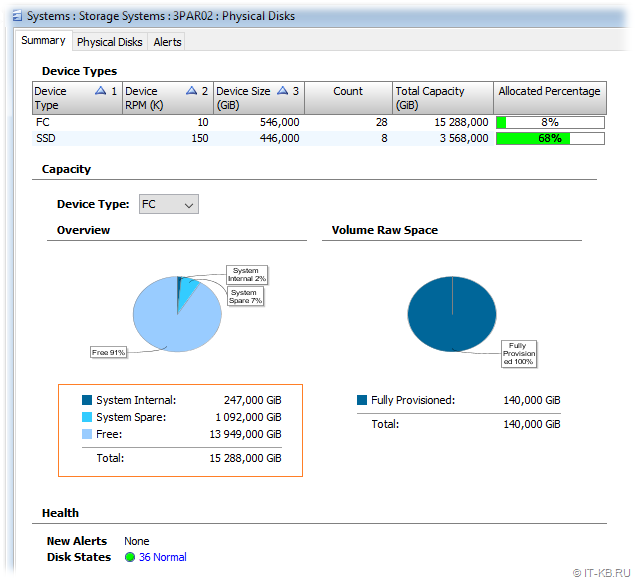
Как видно, в нашем случае емкость двух чанклетов, ранее отнесённых к категории "Failed" перешла в категорию "Free".
В результате мы добились поставленной задачи и избавились от двух неисправных чанклетов, оставив при этом все ранее используемые диски в работе.
 RSS - Записи
RSS - Записи
Добавить комментарий