![]() В это части мы рассмотрим механизмы Fencing, с помощью которых повышается уровень доступности как самих хостов виртуализации, так и выполняемых на этих хостах виртуальных машин в oVirt 4.0. Подробно о принципах и последовательности работы механизмов Fencing в oVirt можно почитать в документе Automatic Fencing. Здесь же мы поговорим об этих механизмах обзорно и рассмотрим несколько практических примеров.
В это части мы рассмотрим механизмы Fencing, с помощью которых повышается уровень доступности как самих хостов виртуализации, так и выполняемых на этих хостах виртуальных машин в oVirt 4.0. Подробно о принципах и последовательности работы механизмов Fencing в oVirt можно почитать в документе Automatic Fencing. Здесь же мы поговорим об этих механизмах обзорно и рассмотрим несколько практических примеров.
Fencing это процесс перезапуска неисправных с точки зрения oVirt Engine компонент, таких, как хостовые службы управления VDSM (Soft-Fencing) и сами хосты виртуализации (Hard-Fencing).
Во всех случаях для успешной работы Fencing требуется наличие Fence Proxy, в качестве которого может выступать другой доступный хост виртуализации, то есть Fencing будет работать при условии, что в кластере oVirt есть хотя бы один работоспособный хост с работающей ВМ Hosted Engine. Fence Proxy выступает в качестве непосредственного инициатора команд восстановления отправляемых удалённо на проблемный хост.
В случае, если oVirt Engine выявляет проблему с доступностью хоста, выполняется симбиоз процессов Soft-Fencing и Hard-Fencing, в зависимости от текущей ситуации. Soft-Fencing выполняется с помощью удалённого SSH-подключения на проблемный хост и приводит к перезапуску службы управления хостом (vdsmd). Процедура Hard-Fencing использует утилиты с именами формата /usr/sbin/fence_*, расположенные на хостах, для удалённой отправки команд на физическую остановку/запуск хоста виртуализации через имеющийся у него аппаратный контроллер управления стандарта IPMI (Intelligent Platform Management Interface). Примером таких контроллеров могут выступать iLO на серверах Hewlett-Packard, DRAC на серверах Dell, ILOM на серверах Sun/Oracle и т.п. Если используемые у вас серверы не имеют IPMI-совместимых контроллеров, но есть управляемые модули распределения питания PDU (Power Distribution Unit), то можно и их использовать для Hard-Fencing oVirt. Помимо задачи восстановления работоспособности, Fencing решает ещё одну важную задачу, - определяет признак того, что виртуальные машины упавшего хоста можно перезапустить на других хостах кластера. Это необходимо для предотвращения записи двумя гипервизорами в диск одной виртуальной машины, что само по себе может привести к невосстановимой порче диска ВМ.
Проверка работы Soft-Fencing
Механизм Soft-Fencing работает на хостах кластера oVirt по умолчанию и не требует никакой специальной настройки. Для того, чтобы проверить его работоспособность, сымитируем на одном из наших хостов (KOM-AD01-VM31) отказ службы VDSM. Для этого сначала выясним идентификатор PID главного процесса службы vdsmd:
# service vdsmd status | grep "Main PID" Redirecting to /bin/systemctl status vdsmd.service Main PID: 2997 (vdsm)
"Уроним" этот процесс, отправив ему сигнал SIGKILL:
# kill -9 2997
После этого в веб-консоли oVirt статус нашего подопытного хоста изменится с Up на Connecting

Буквально через несколько секунд Engine выберет из доступных работоспособных хостов прокси-хост (KOM-AD01-VM32), c которого будет сначала будет запущена процедура Hard-Fencing c командой status (для проверки, включён ли проблемный хост физически), затем выполнена попытка Soft-Fencing, то есть отправка по протоколу SSH на проблемный хост команды восстановления службы vdsmd. Все эти активности можно будет наблюдать в веб-консоли oVirt:

Как видим, в нашем примере полное время реакции oVirt Engine на проблему, с учётом автоматического исправления этой проблемы, получилось не больше 20 секунд. И это хорошо.
Настройка Power Managment для хостов виртуализации
Для обеспечения работы механизма Hard-Fencing нам потребуется выполнить в oVirt настройку Power Management, то есть на уровне хоста виртуализации задать настройки Fence Agent. В качестве Fence Agent, как уже ранее говорилось могут выступать контроллеры IPMI либо управляемые PDU. Перед тем, как приступить к настройке параметров в oVirt, мы должны произвести настройку самих управляющих контроллеров/устройств. В нашем случае в качестве хостов виртуализации используются серверы HP ProLiant DL 360 G5 и поэтому нам доступны их контроллеры управления iLO2. Подключимся к iLO и на вкладках Administration > User Administration создадим под нашу задачу отдельного пользователя, например с именем oVirt-PM-Agent. Зададим пользователю сложный пароль и ограничим в правах таким образом, чтобы этому пользователю были доступны только функции управления электропитанием сервера, то есть разрешим только Virtual Power and Reset:
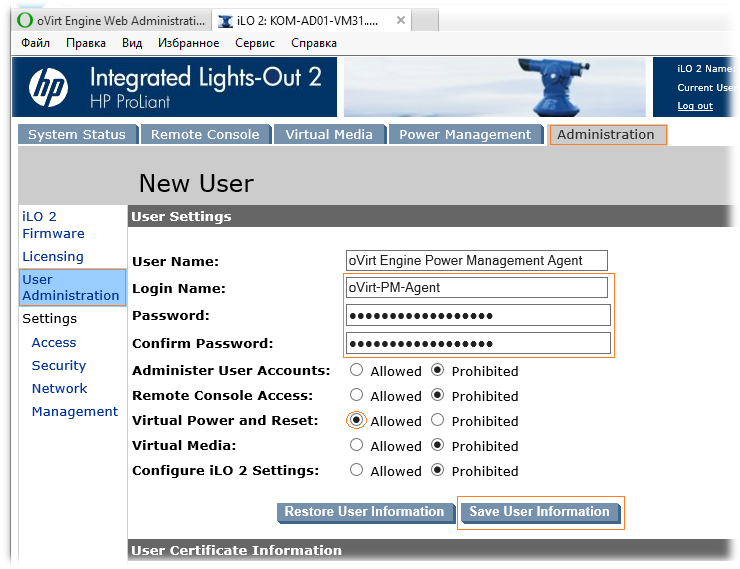
После этого перейдём в веб-консоль oVirt и на закладке Hosts выберем хост, для которого только что настроили iLO. Пока настройка Power Management для хоста не выполнена, мы будем видеть соответствующие предупреждения.
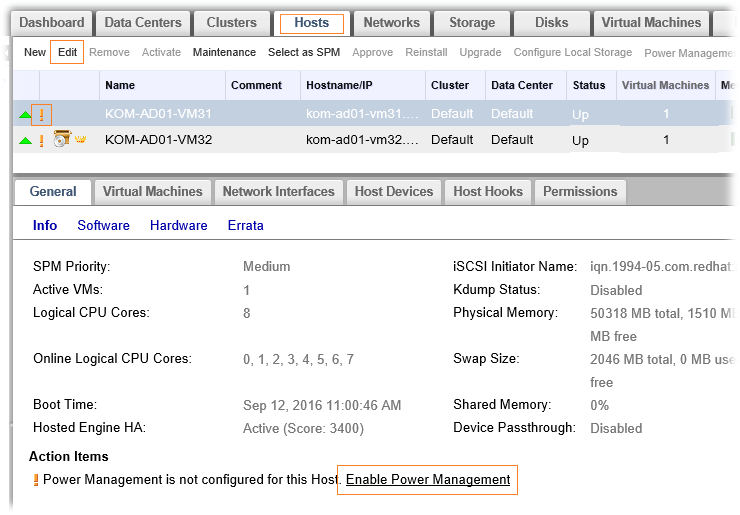
В веб-форме редактирования свойств хоста перейдём на вкладку Power Management и воспользуемся кнопкой добавления Fence Agent.

В форме добавления агента введём адрес нашего iLO контроллера и учётные данные ранее созданного на iLO пользователя. В поле Type выберем тип агента соответствующий нашему случаю. В поле Options введём через запятые набор опций, относящихся к тому или иному Fencing-агенту.
Для iLO2 я использовал следующий список параметров:
ssl=yes,ssl_insecure=yes,inet4_only=yes
Вызываемые для Hard-Fencing на хостах утилиты с именами формата /usr/sbin/fence_* имеют, как man-страницы, так и встроенную короткую справку по возможным параметрам, как правило, такую справку можно вызвать ключом -h:
# fence_ilo2 -h
Соответственно, при проблемах с настройкой подключения Fencing-агента того или иного типа, для диагностики можно вызывать соответствующие этому типу утилиты на каком нибудь из хостов, например следующим образом:
# fence_ilo2 -a kom-ad01-ilo31 -l oVirt-PM-Agent -p MyStr0nGP@ss -o status --ssl --inet4-only --ssl-insecure -v

Закончив настройку параметров, жмём кнопку Test, чтобы убедиться в том, что введённые параметры позволяют удалённо подключиться к Fencing-агенту и получить текущий статус хоста, например в нашем случае получено сообщение о том, что тест прошёл успешно, так как получено текущее состояние хоста - power on.
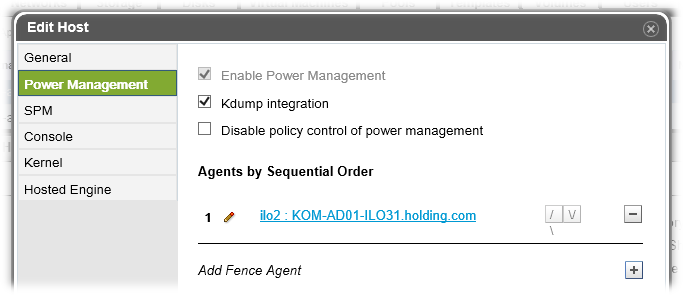
При необходимости мы можем добавить дополнительных Fencing-агентов, а также настроить приоритет их использования, что может значительно повысить шансы на правильную отработку механизмов Fencing. И это хорошо.
После настройки Power Management у нас появится дополнительная удобная функция управления включением/выключением/перезагрузкой хоста непосредственно из интерфейса веб-консоли oVirt:
 Настройка Power Management завершена и теперь можно перейти к тестированию Hard-Fencing.
Настройка Power Management завершена и теперь можно перейти к тестированию Hard-Fencing.
Проверка обработки отказа узла кластера с помощью Hard-Fencing
Чтобы выполнить проверку процедуры обработки отказа узла кластера oVirt, когда хост (KOM-AD01-VM31), на котором в данный момент запущена виртуальная машина (KOM-AD01-PBX02), резко станет недоступен, я решил сымитировать сбой сетевой системы этого хоста. Я подключился к коммутатору Cisco, к которому были подключены порты сервера виртуализации и физически выключил эти порты. Так как в моём случае сервер подключён к коммутатору своими двумя физическим интерфейсами, входящими на коммутаторе в виртуальную группу портов channel-group с LACP, то мне достаточно было отключить агрегированный интерфейс группы:
switch# configure terminal switch(config)# interface Port-channel1 switch(config-if)# shutdown switch(config-if)# end
Предварительно я запустил ping до виртуальной машины, которая была расположена на этом хосте.
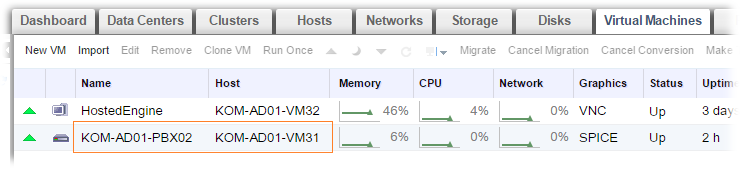
После того, как на bond-интерфейсе хоста пропал доступ к сети, и как следствие перестала отвечать служба VDSM с хоста, oVirt Engine обнаруживает это и инициирует запуск механизмов Fencing, изменив статут хоста на Connecting.

Через пару минут статус хоста меняется на Non Responsive и запускается процедура физического перезапуска сервера с помощью Fencing-агента (напомню, что в нашем случае это iLO2 контроллер). После этого, убедившись в том, что процедура физического перезапуска сервера с недоступной виртуальной машиной выполнена успешно (напомню, что это нужно для предотвращения ситуации с записью в диск одной ВМ с разных хостов), oVirt Engine инициирует процесс запуска виртуальной машины на другом доступном хосте виртуализации (KOM-AD01-VM32): 
Если заглянуть в аппаратный лог iLO-контроллера, то за соответствующий отрезок времени мы сможем увидеть активности нашего Fencing-агента:

В конечном итоге, на автоматическое восстановление доступности виртуальной машины, которая была запущена на проблемном хосте ушло около 4 минут. И это, на мой взгляд, хороший показатель. Таким образом, можно считать, что проверка обработки отказа хоста в oVirt 4.0 прошла успешно.
Исключительные ситуации полной недоступности хоста
На практике можно столкнуться с ситуациями, когда происходит полная изоляция хоста виртуализации, то есть с точки зрения oVirt Engine становится недоступна как хостовая система (нет связи с хостовой службой VDSM), так и все настроенные для этого сервера Fencing-агенты (IPMI/PDU). Такое возможно, когда например администратор не позаботился об избыточности аппаратных компонент сервера и ввёл в эксплуатацию сервер с одним блоком питания, а этот блок питания внезапно вышел из строя и сервер полностью обесточился. Как мы понимаем, в такой и подобных ситуациях встроенные в oVirt механизмы Fencing не смогут выполнить свои задачи и восстановить доступность хоста и его виртуальных машин. Такие обстоятельства приводят к тому, что oVirt не способен гарантированно определить тот факт, что диски виртуальных машин, расположенных на "отвалившемся" хосте всё ещё не продолжают использоваться на общем хранилище, подключённом к хосту, например, по Fibre Сhannel. И для полного исключения рисков порчи дисков таких виртуальных машин, oVirt Engine не пытается выполнить их перезапуск на других хостах, а ждёт вмешательства администратора. Рассмотрим практический пример такой ситуации. Вернём наш многострадальный подопытный хост KOM-AD01-VM31 в исходное работоспособное состояние и мигрируем на него виртуальную машину KOM-AD01-PBX02.
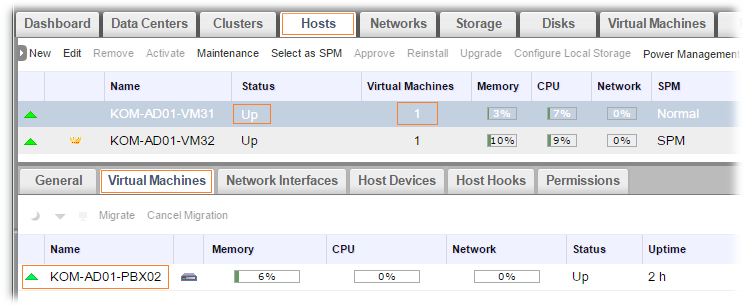
Теперь сымитируем полный сбой сервера, физически вытащив из него кабели подачи электропитания. После нескольких попыток подключения к Fencing-агенту хост перейдёт в статус Non Responsive, а виртуальные машины, которые были на нём запущены поменяют статус на Unknown. В нижней части экрана, где отображается упрощённый живой лог текущих событий oVirt во вкладке Alerts, мы сможем увидеть рекомендацию по выполнению дополнительного действия над проблемным хостом.

После того, как администратор убедился в том, что сервер не имеет активного подключения к SAN, и, как следствие, не возможна модификация дисков виртуальных машин с этого сервера на общем хранилище, выполняется функция Confirm 'Host has been Rebooted'. Эта функция даёт со стороны администратора разрешение управляющему коду oVirt Engine на запуск виртуальных машин с "упавшего" хоста на других доступных хостах.

При выборе этого пункта меню администратор получает предупреждение о том, что несвоевременное использование данной функции может привести к порче данных виртуальных машин и необходимо подтвердить то, что мы понимаем то, что мы делаем:
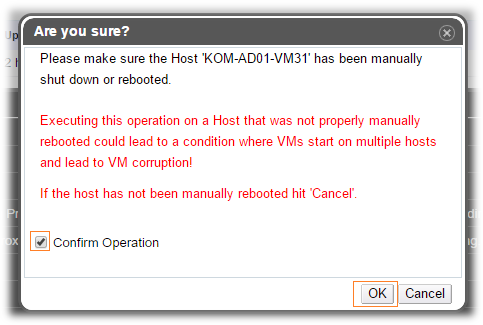
Сразу после нажатия кнопки OK в данной форме будет изменён статус всех виртуальных машин с недоступного хоста на Down, после чего для виртуальных машин, имеющих включённую опцию Highly Available, будет инициирован их запуск на доступных хостах виртуализации.

***
Как я понял, на данный момент у команды разработчиков oVirt есть планы по реализации дополнительных механизмов Fencing, которые могут расширить возможности автоматической обработки отказов в разных ситуациях. Например к таким механизмам можно отнести находящийся в разработке Sanlock Fencing, который должен будет позволить обрабатывать ситуации отказа хоста на уровне хранилища SAN, то есть увеличит количество ситуаций, при которых не потребуется ручного вмешательства администратора и позволит безопасно выполнять автоматический перезапуск виртуальных машин на доступных хостах.
Подводя итог, исходя из последнего описанного примера, текущий уровень поддержки высокой доступности в oVirt, на мой взгляд, на текущий момент нельзя назвать беспрецедентным, однако стоит отдельно отменить тот факт, что продукт интенсивно развивается. И это хорошо.
В следующей части мы рассмотрим ещё одно средство повышения доступности, которое нам предоставляет oVirt 4.0. Речь пойдёт про использование виртуальных Watchdog-устройств, как средства повышения доступности гостевых систем виртуальных машин.
Дополнительные источники информации:
- Видео Евгения Деревянкина - oVirt - часть 5 - High Availability
- Видео Eli Mesika - oVirt fencing and power management deep dive
- Видео Martin Peřina - Host fencing in oVirt - Fixing the unknown and allowing VMs to be highly available
- Red Hat Enterprise Virtualization Manager Administration Guide - 6.6. Host Resilience
 RSS - Записи
RSS - Записи
Обратная ссылка: Развёртывание и настройка oVirt 4.0. Часть 5. Watchdog как средство повышения доступности гостевых систем виртуальных машин | Блог IT-KB /
у вас какая-то беда со шрифтами в заголовках все с боооольшими интервалами. Хром, макос.
Проверил на трёх разных ОС (Windows/Kubuntu Linux/Andriod) в разных браузерах, в том числе и в Chrome на Windows/Chromium на Linux/Chrome на Android. Всё в порядке. Так что не надо "бабушку лохматить".
Проблема только на MacOS причем во всех сразу браузерах. Шрифта там такого нет, который Вы используете в своих заголовках.
Вопрос - а не сталкивались с Intel AMT? У нас в основном IPMI, работает на ура, но затесалась пара нод и с AMT. Вроде тоже позволяет fencing (во всяком случае встречал в сети sh скрипт, который позволяет управлять питанием), а вот fencing агента в oVirt не нашёл, приходится эти ноды использовать для экспериментов и ВМ, не требующих HA... Или я что-то делаю не так?
Тут говорят, что fence-агент для AMT, как минимум, есть под Fedora https://iranzo.github.io/blog/2015/05/01/intel-amt-on-linux-for-remote-control-slash-fencing/. Поэтому вполне возможно, что есть вариант реализации и для CentOS. Попробуйте задать вопрос в мэйл-группу oVirt http://lists.ovirt.org/mailman/listinfo/users
1. Заметил на ваших скриптак в информации о хосте "SELinux mode: Enforcing." :)
2. "Механизм Soft-Fencing работает на хостах кластера oVirt по умолчанию и не требует никакой специальной настройки."
"После настройки Power Management у нас появится дополнительная удобная функция управления включением/выключением/перезагрузкой хоста непосредственно из интерфейса веб-консоли oVirt"
Странно, а что мешает изначально активировать меню "Power Management"? Ведь ovirt должен иметь возможность ребутнуть или выключить хост штатными средствами через "Soft-Fencing" (SSH). Hard reset само собой нужен Hard-Fencing, тут без вопросов.
3. "Fencing будет работать при условии, что в кластере oVirt есть хотя бы один работоспособный хост с работающей ВМ Hosted Engine."
"Такие обстоятельства приводят к тому, что oVirt не способен гарантированно определить тот факт, что диски виртуальных машин, расположенных на «отвалившемся» хосте всё ещё не продолжают использоваться на общем хранилище, подключённом к хосту, например, по Fibre Сhannel."
В vmware HA кластеру не нужен vCenter.
Автоматизирован HA слабовато. Будем ждать Sanlock Fencing.
1. а что тут не так?
2. софт-фенс недостаточен для SBA, если отвалилась сеть через которую он доступен, но при этом пара десятков VM на хосте прекрасно себя чувствуют, как знать что можно поднимать эти VM на другом хосте не убив им диски сплитбрейном?
3. в оВирт вся HA логика находится в engine. Это сильно упрощает разработку и сам алгоритм SBA, и делает его более надежным, но создает узкое место - нет engine, нет HA. Решений тут несколько, от просто установки engine в отдельный HA кластер, self-hosted engine, с собственным HA механизмом как в ЕSXi, и до переноса VM-HA на уровень vdsm. Последнее очень трудоемко, и не очень нужно на самом деле. Engine легко защитить, а когда он работает, VM HA работает на ура. Я этот вопрос очень глубоко изучал, сравнивал и тестировал целую кучу подобных и не очень систем
1. Наоборот, просто Алексей не собирался внедрять. Я помню, что вы писали про замечательный sVirt, видимо он автоматом встает. Так просто обратил внимание. Это не вопрос.
2. Могли бы вы расшифровывать сокращения :) Не знаю пока что такое SBA :) Мой вопрос в этом пункте был про "Странно, а что мешает изначально активировать меню «Power Management»? ". «Soft-Fencing» (SSH) может и не достаточно для описанной Вами ситуации, но его должно быть достаточно если я хочу ребутнуть полночтью рабочий хост, поэтому по моей логике это меню должно работать изначально ... если, конечно, нет еще одного меню, через которое можно ребутнуть хост :)
2.1. А то, что вы описали в vmware обходится заложенным в хосты порядком действий и запасом времени. При условии полной изоляции механизм проверки запускается на обоих концах изоляции, если правильно помню, то примерно 30 мин это занимает + не надо ждать админа ... из отпуска :) Если полная изоляция машинка уже не может связаться с датастором, а если дата сеть доступна, то хост просто культурно ее выключит и разлочит ее. Если датастор недоступен ... то уже через 60 сек оэидания машинка всеравно мертва ... 30 мин ожидания с лихвой хватает. Но где-то вы говорили, что у oVirt есть механизм, который умеет автоматом замараживать машинки, и при этом тогда в идеале он должен их мигрировать на другой хост замароженными, если нет, тогда ожидание админа безусловно кастыль.
3. Да, подходит. Спасибо.
"Наоборот, просто Алексей не собирался внедрять". Это не более, чем Ваши домыслы.
Вырезка из комментраиев к первой части.
Я - "Планируете ли или используете ли SELinux?"
Вы - "По поводу SELinux, вообще я думал, что это дополнительный механизм защиты исполнения процессов в системе, поэтому вопрос применительно к виртуализации мне не понятен."
Из этих слов я сделал, видимо, неверный вывод, прошу прощения. Но в комменте я указал на SELinux не из-за этого, а из-за того, что если вы действительно не собирались ковыряться с SELinux, а на скринах он есть и в консоли я не видел, чтобы ставился sVirt отдельн, значит его установка прошла настолько же скрытно на сколько и гладко. И именно это меня очень порадовало.
Написал длинный ответ, но все пропало на 500 server error :)
Знакомо, поэтому всегда сначала копирую текст перед отправкой :)
2. SBA = split brain avoidance. Это stonith, paxos, quorum и все что вокруг во всех своих имплементациях и вариациях.
Power Management - это буквально управление питанием. Через SSH я не могу включить выключенный хост например, не могу форсировать выключение. Короче это не одно и то же. Ребут на хост делать в штатных ситуациях ни к чему в любом случае, кстати.
2.1 механизм vmware более продвинут, но и более подвержен потенциальным splitbrain. оВирт использует простой и надежный как лом STONITH. Что для вас важнее, сохранность данных на диске VM, или навороченность алгоритма?
Заморозка машин при проблемах с датастором это не только заморозка, если хост теряет доступ к датастору, то он уходит в специальный статус, где получит fence, a значит все HA машины будут рестартованы. Но если проблема у одной единственной машины, то бить целый хост ради нее - идиотизм. А рестарт такой машины на другом хосте вряд ли исправит проблему с индивидуальным диском одной конкретной машины, и тут нужно вмешательство админа.
Если резюмировать, то я пытаюсь прояснить одну простую вещь - vmware может казаться эталоном того как виртуализация должна работать, но это зачастую не так. Они раньше других начали, и наделали кучу ошибок, которых более поздние системы смогли легко избежать, просто не залезая в те дебри. Это касается очень многого - и проблемы с PR, и gang scheduling, и идиотский UI, и еще многое. Об этом очень мало пишут не потому что этого нет, а потому что критика vmware обычно чревата последствиями (почитайте их EULA). А отдав изрядную сумму в долларах за софт, терять лицензию обычно никто не хочет, и проблемы несут не в публичные форумы и блоги, а в техподдержку.
2. Короче без IPMI, PDU и т. д. хост через админ панель не выключить? Рахные ситуации бывают.
3. Речь шла о полной изоляции хоста, но я могу рассказать и про ВМ конкретную :) но не виижу смысла :)
я не считаю vmware эталоном, но он обще признанный лидер по квадрату Gartner.
Про UI прям в точку :) Тормознутая вебка + невозможность скопировать 90% текста элементарным выделением ... прям бесит до дрожи. Vmware Workstation тоже подбешивает, но esxi получился нормально со старым толстым клиентом.
А сравниваю я с vmware, потомучто работаю с ним и знаю что там к чему и пытаюсь нащупать те вещи, которыми пользуюсь и которые нужны.
2. Именно так, не выключить. Выключать без возможности включить - это не управление а стрельба по собственным конечностям :)
3. я знаю как оно работает, и я думаю что потихоньку и это добавят, как опцию дополняющую STONITH
4. UI который пашет только на винде, даже если он более функционален чем веб, это тоже извращение. Ну да ладно, не суть. Я на самом деле хотел бы видеть вопросы в форуме, там легче отслеживать ответы, комментировать и т.д. И еще - вы уже поставили oVirt? Поставьте, тогда будет множество вопросов :)
Пока не ставил oVirt. Хочу дочитать все статьи Максима. Вопросы касающиеся статей пишу к статьям. Попутно зреют вопросы не совсем касающиеся статей, их под коплю и на форум. Просто бывает читают с телефона статью, попутно готовлю коммент, дочитав до конца вопрос снимается :)
Спасибо за ваши ответы ;)
Обратная ссылка: Развёртывание и настройка oVirt 4.0. Часть 13. Настройка службы оповещений | Блог IT-KB /
Обратная ссылка: Развёртывание и настройка oVirt 4.0. Часть 7. Расширение кластера и балансировка нагрузки | Блог IT-KB /