![]() Когда-то мы уже рассматривали вариант организации дедуплицированного хранилища резервных копий виртуальных машин oVirt с помощью ПО QUADStor Storage Virtualization на CentOS Linux 7.2. Со временем описанная в той заметке конфигурация была переведена на ОС Debian GNU/Linux 9 и так работала до тех пор, пока нас не стало напрягать время остановки и запуска службы QUADStor тогда, когда требовалась перезагрузка хоста. Было решено попробовать возможности дедупликации Virtual Data Optimizer (VDO) в составе CentOS Linux 7 в качестве альтернативы дедупликации от QUADStor. В этой заметке мы и рассмотрим базовые теоретические моменты использования VDO с практическим примером применительно к нашей задаче резервного копирования виртуальных машин.
Когда-то мы уже рассматривали вариант организации дедуплицированного хранилища резервных копий виртуальных машин oVirt с помощью ПО QUADStor Storage Virtualization на CentOS Linux 7.2. Со временем описанная в той заметке конфигурация была переведена на ОС Debian GNU/Linux 9 и так работала до тех пор, пока нас не стало напрягать время остановки и запуска службы QUADStor тогда, когда требовалась перезагрузка хоста. Было решено попробовать возможности дедупликации Virtual Data Optimizer (VDO) в составе CentOS Linux 7 в качестве альтернативы дедупликации от QUADStor. В этой заметке мы и рассмотрим базовые теоретические моменты использования VDO с практическим примером применительно к нашей задаче резервного копирования виртуальных машин.
В рассматриваемом далее примере, под задачу хранения резервных копий виртуальных машины oVirt с дедупликацией, в отдельном кластере Hyper-V развёрнут выделенный виртуальный сервер с гостевой ОС CentOS Linux 7.5. К этому виртуальному серверу, по аналогии с ранее упомянутой заметкой, через FC SAN с Multipath со старого дискового хранилища подключены 12 дисков SATA 500GB. В гостевой ОС CentOS диски собраны в программный массив RAID-6. На этом RAID-массиве мы и попробуем создать том VDO с дедупликацией, но сначала немного теории.
С теоретическими основами технологии VDO можно ознакомится в онлайн-документе Red Hat Enterprise Linux 7 Storage Administration Guide - Chapter 29. VDO Integration, либо, загрузив оффлайн-копию этого документа в формате PDF.
Далее приведу небольшой вольный перевод некоторых положений теоретической части об архитектуре VDO, который, как мы понимаем, не заменяет чтения официальной документации по технологии.
Архитектура VDO
Virtual Data Optimizer (VDO) - это технология виртуализации блочных устройств, позволяющая создавать из блочных устройств виртуальные пулы с поддержкой онлайн-компрессии и онлайн-дедупликации.
VDO в CentOS 7.5 представлен двумя ядерными модулями - kvdo (работает на уровне Linux Device Mapper) и uds (работает с индексом дедупликации Universal Deduplication Service).
Виртуальный дисковый том VDO представляет собой надстройку над блочным устройством и состоит из раздела VDO, в котором хранятся дедуплицированные блоки данных, и раздела UDS, где хранятся индексные метаданные дедупликации.

Том VDO разбит на смежные одноразмерные ячейки, называемые Slab. Размер такой ячейки может колебаться от 128MB до 32GB и влияет на размер тома VDO. Размер ячейки задаётся на этапе создания тома VDO и по умолчанию составляет 2GB. Так, как один том VDO максимально может содержать до 8096 ячеек, соответственно максимальный размер тома VDO зависит от выбранного размера ячейки. Приведу копию таблицы с рекомендованными размерами ячеек при создании VDO тома из документации.
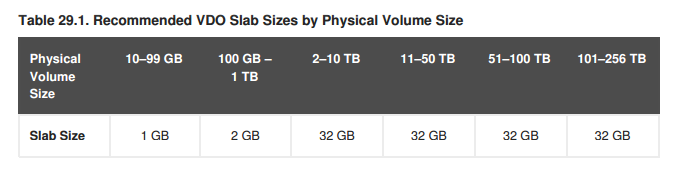 Таким образом, максимальный размер VDO тома при максимальном размере ячейки в 32GB может достигать 256TB. Из общего количества ячеек, как минимум, одна ячейка всегда зарезервирована под хранение метаданных VDO.
Таким образом, максимальный размер VDO тома при максимальном размере ячейки в 32GB может достигать 256TB. Из общего количества ячеек, как минимум, одна ячейка всегда зарезервирована под хранение метаданных VDO.
Исходя из всей представленной информации, физический размер тома VDO, доступный для пользовательских данных (Available physical size), вычисляется как физический размер тома VDO (Physical size) минус размер метаданных (ячейки индекса UDS) и минус остатки, образовавшиеся от деления тома на ячейки равного размера.
Логический размер тома VDO (Logical Size) при его здании по умолчанию равен физическому размеру тома, если явно не указано иное. Логический размер тома может превосходить его физический размер до 254 раз и достигать 4PB.
Манипулировать томами VDO нам позволит утилита vdo, а с помощью утилиты vdostats мы сможем получить статистическую информацию о текущем уровне утилизации и производительности томов VDO.
Требования для эксплуатации томов VDO
С точки зрения системных требований следует учитывать следующие моменты:
1) Нужен 64-битный процессор AMD или Intel.
2) Обслуживание каждого тома VDO с точки зрения потребления оперативной памяти требует:
Из программных требований отмечены LVM и Python 2.7.
С точки зрения размещения, слой VDO может использоваться над уровнем управления дисковыми устройствами (в том числе DM-Multipath, DM-Crypt и программных RAID-массивов LVM или mdraid) и под уровнем управления логическими дисками (в том числе LVM cache, LVM Logical Volumes, LVM snapshots, LVM Thin Provisioning). Работа с разделами на томе VDO такими инструментами, как fdisk, parted и т.п., не допускается. Построение программных RAID поверх VDO не допускается.
Расчёт ресурсов памяти
Рассчитаем сколько нужно ОЗУ для нашего виртуального сервера для обеспечения работы VDO.
Расчёты будем производить исходя из того, что под хранилище oVirt Export Domain планируется отдать RAID-массив размером 4999,38GB. Всю указанную ёмкость этого массива мы будем использовать для создания тома VDO.
Учитывая то, что согласно вышеприведённой таблице, наша дисковая ёмкость попадает в категорию 2-10TB, размер ячейки будущего тома будем использовать в рекомендованном размере 32GB. Исходя из такого размера ячейки и доступной физической ёмкости, понимаем, что наш VDO том сможет содержать 156 ячеек общим размером в 4992GB.
Для работы модуля vdo нам потребуется 1710MB ОЗУ (370MB + 268MB * ~5TB). Для работы модуля uds мы будем рассчитывать ориентировочно на 1GB ОЗУ. Таким образом, грубо округляя, получается, что в нашем случае для штатной работы VDO должно быть достаточно 4GB ОЗУ. Хотя, если в документации смотреть раздел 29.2.3, в нашем сценарии использования дисковой ёмкости VDO под задачу резервного копирования, нам будет достаточно и 2GB ОЗУ.

Я выделю виртуальной машине 8GB ОЗУ, чтобы в дальнейшем оценить то, как на самом деле будет потреблять память система.
Установка VDO и создание виртуального тома
Для установки поддержки VDO в CentOS 7.5 достаточно установить пару пакетов:
# yum install vdo kmod-kvdo
С помощью утилиты vdo создадим на базе имеющегося в нашем примере блочного устройства /dev/md0 том VDO c размером ячейки в 32GB и логическим размером в трое превышающим физический размер блочного устройства, то есть 15TB:
# vdo create --name=vdo1 \ --device=/dev/disk/by-id/md-uuid-3161ebbe:a270f3e8:376f17d0:41130125 \ --vdoLogicalSize=15T \ --vdoSlabSize=32G \ --blockMapCacheSize=256M \ --readCache=enabled --readCacheSize=128M \ --sparseIndex=enabled \ --force --verbose
Обратите внимание на то, что при указании пути к блочному устройству важно использовать постоянное имя устройства, которое не меняется в зависимости от разных обстоятельств. Например, при использовании устройств mdraid лучше использовать не имя /dev/md0, а путь к устройству по его MD UUID (путь типа /dev/disk/by-id/md-uuid-). Для обычных дисковых устройств можно использовать идентификаторы типа SCSI ID (путь типа /dev/disk/by-id/scsi-)
Значение параметра blockMapCacheSize в нашем примере определено в 256MB, а по умолчанию (если значение не указано явно) оно составляет 128MB. Увеличение этого значения может быть полезно можно увеличивать в том числе и для нагрузок со случайным доступом.
Параметр
readCache нами включён дополнительно, а по умолчанию он выключен. Соответственно,
значение readCacheSize мы установили в 128M (8MB минимум).
Относительно параметра sparseIndex в разделе документации 29.4.4. Configuring the UDS Index отмечено, что желательно использовать разреженный индекс (Sparse Index), который даёт дополнительные накладные расходы, но при этом улучшает эффективность работы UDS. По умолчанию (без явного указания) используется компактный индекс (Dense Index). Он менее требователен к ресурсам, но и также менее эффективен.
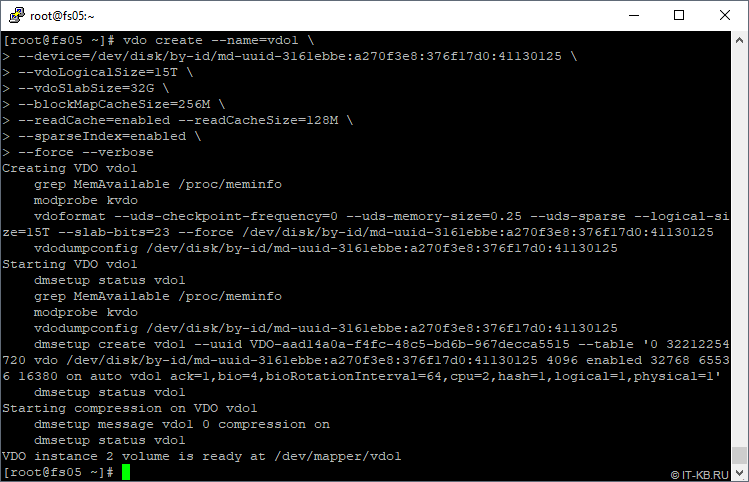
После создания первого тома VDO заглянем в автоматически сформированный в системе конфигурационный файл vdoconf.yml
# cat /etc/vdoconf.yml
Здесь обратим внимание на размеры кешей и ячейки. Они должны соответствовать заданным в ходе создания тома значениям. Опция activated определяет автозагрузку тома VDO при включении системы.
Посмотрим статистическую информацию о томе с точки зрения VDO и с точки зрения того, как видит система новое блочное устройство vdo1:
# vdostats --human-readable # lsblk /dev/mapper/vdo1
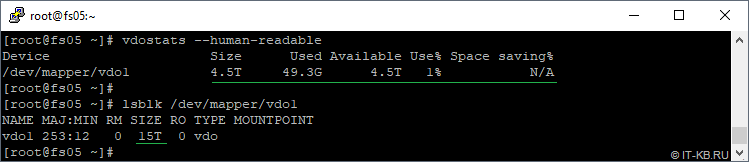
Здесь в показателе Used мы видим, что часть тома VDO уже используется метаданными и индексом UDS. Размер 49.3G в моём случае обусловлен включением sparseIndex (без включения первичное состояние служебных данных занимало около 17G)
Дополнительные команды просмотра состояния VDO и статистик виртуальных томов VDO, дающие больше информации, выглядят так:
# vdo status # vdostats --verbose
Итак, том VDO создан и работает. Теперь можно создавать на этом томе нужную нам файловую систему.
Создание файловой системы и монтирование
Создадим на томе VDO раздел с файловой системой XFS, затем создадим каталог под точку монтирования и смонтируем туда наш XFS-раздел.
# mkfs.xfs -K /dev/mapper/vdo1 # mkdir -m 1777 /mnt/vdo-vd1 # mount /dev/mapper/vdo1 /mnt/vdo-vd1
Для того, чтобы раздел монтировался автоматически при запуске системы добавим информацию о нём в fstab. Но сначала выясним UUID тома VDO:
# blkid /dev/mapper/vdo1 /dev/mapper/vdo1: UUID="6f1d4cb3-13a5-4e01-9151-f6630a821d4b" TYPE="xfs"
Добавим в конец файла /etc/fstab строку монтирования тома VDO с зависимостью от службы vdo.service:
# Mount VDO virtual disk # UUID=6f1d4cb3-13a5-4e01-9151-f6630a821d4b /mnt/vdo-vd1 xfs defaults,x-systemd.requires=vdo.service 0 0
После этого перезагрузим систему, чтобы убедиться в том, что в процессе запуска том VDO успешно монтируется и доступен нам для использования.
На этом базовую процедуру развёртывания тома VDO с онлайн-дедупликацией и компрессией можно считать законченной.
Испытания и выводы
Мы не будем проводить каких-то принципиальных сравнений скорости работы дедупликации от QUADStor с дедупликацией, которую даёт VDO. Так как в нашем случае, имеющаяся на момент развёртывания инфраструктура QUADStor отличается по многим показателям от виртуальной машины с VDO. Поэтому говорить об объективности тут не приходится. Однако по опыту дальнейшего использования VDO можем отметить ряд преимуществ VDO.
Наш субъективный взгляд одним из главных плюсов VDO является то, что программную дедупликацию в CentOS Linux 7 можно получить почти "из-коробки" без установки стороннего ПО и, в некоторых ситуациях, плясок вокруг модулей ядра, несовместимости драйверов и других странностей в случае использования QUADStor.
Запуск процедуры резервного копирования одной небольшой (~10GB)виртуальной машины на том VDO не вызывает в гостевой ОС сервера резервного копирования (с томом VDO) никаких существенных всплесков нагрузки.
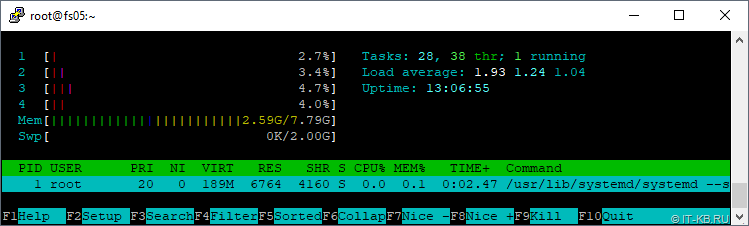
За время активного использования сервера резервного копирования при ежедневном резервном копировании двух десятков виртуальных машин oVirt (при размере ВМ от 10GB до 450GB) график процессорной нагрузки выглядит вполне скромно:
Потребление памяти, выделенной в нашем выше описанном примере для ВМ в размере 8GB, при этом также оказалось избыточным и никогда не поднималось выше 40%. При всём при этом время выключения и включения сервера с VDO просто несоизмеримо со временем, которое имеет QUADStor Storage Virtualization работая со своими тяжёлыми кэшами и метаданными.
 RSS - Записи
RSS - Записи
Добрый день, Алексей!
Из статьи видится, что вы по прежнему используете oVirt в своей ИТ инфраструктуре.
У вас есть отличная статья по резервному копированию виртуальных машин из oVirt, однако она датирована "далеким" 2016 годом и комментарии (в том числе и мои) по поводу решений по резервному копированию там уже иссякли.
Хотел уточнить у вас, есть ли опыт использования сторонних решений (кроме скриптов) по резервному копированию и если есть и это информация не КТ, что используете и нравится ли вам используемое решение.
Доброго времени суток, Павел. На данный момент времени для резервного копирования ВМ oVirt 4.2.7 используем всё тот же скрипт с описанной здесь технологией дедупликации. Других решений не пробовал.
Алексей, не знаю интересно ли вам, но поделюсь кратко нашими изысканиями в этой области.
Есть ребята в Чехии, которые производят продукт по названием vProtect (хотя мы и не используем его, однако следим за его развитием), продукт для резервного копирования в том числе виртуальных машин из oVirt. Один из них пояснил работу своего продукта в статье (https://www.openvirtualization.pro/agent-less-backup-strategies-for-ovirt-rhv-environments/), я думаю, что в вашем случае можно замутить 3 стратегию используя API, это должно уменьшит время (если конечно оно критично в вашем случае) резервного копирования.
Лично мы используем Commvault, который использует 2 стратегию. Он конечно не идеален, но позволяет довольно гибко управлять резервным копированием. Commvault умеет делать инкрементальную копия (неважно какого типа диск QCOW или RAW), но для этого ему нужно все равно прочитать весь диск виртуальной машины, другие словами полный бэкап от инкрементального по времени (не по объему) отличается не значительно и это не очень хорошо.
Использовали оба вида дедупликации и VDO и Quadstor. Отказались от обоих.
О проблемах Quadstor автор статьи писал на этом ресурсе много. О недостатках VDO нужно сказать следующее:
1. При линейной записи на блочное устройство наблюдается интенсивное чтение небольшими блоками (рандомное). Очень пагубно для VDO развёрнутого на небыстрых дисках.
2. Обязательно нужно организовывать DISCARD/TRIM. Объём занятого места на физическом устройстве без этого только растёт.
3. Очень внимательно нужно следить за занятым местом. На одной инсталяции упустил это. В результате даже после расширения объёма физического устройства наблюдали периодическое выпадение этого тома VDO в режим read olny. А перевод в RW был возможен только после остановки тома и останавливаться от не хотел. Только после перезагрузки.
4. Том VDO созданный на одном сервере и подключенный к другому серверу не определяется и не стартует. Новый сервер видит сигнатуру, но без файла конфигурации ничего не делает.
Само решение резервного копирования на oVirt/RHEV "snapshot ==> копия VM из снапшота ==> export" для больших объёмов неудачное. В нашей инсталляции ( больше 40-ка nodes ) по такой схеме приходилось перекачивать до 2TB ежедневно.
Отказались в пользу backy2 и стратегию номер 2, как указал предыдущий комментатор.
>до 2TB ежедневно.
и в чём беда? совершенно мелкие объемы.
>Обязательно нужно организовывать DISCARD/TRIM
ну тут уж совсем трудно , ага. сраказм.
Алексей, здравствуйте!
При увеличении размера диска (физ. или lun-a) в данном случае ни каких действий по увеличению дискового раздела vdo1 не требуеться?
только resize2fs для файловой системы?
Здравствуйте, Андрей.
Сейчас у меня нет под руками тома VDO, поэтому сходу ответить не смогу. Проверьте это самостоятельно.